

Dziś taki lekki misz-masz. W uczeniu maszynowym określenie struktury modelu i trening sieci neuronowej to stosunkowo niewielkie elementy dłuższego łańcucha czynności, który rozpoczyna się od załadowania zbioru danych, jego podziału na podzbiory uczący, walidacyjny oraz testowy i odpowiedniego serwowania danych do modelu. Po drodze pojawiają się również takie kwestie jak transformacja danych, uczenie na GPU oraz zbieranie metryk i ich wizualizacja, w celu określenia skuteczności naszego modelu. W niniejszym poście chciałbym skupić się nie tyle na architekturze modelu i na samym uczeniu, co właśnie na tych kilku czynnościach, które często wymagają od nas całkiem sporo czasu i wysiłku. Do kodowania wykorzystana zostanie moja ulubiona biblioteka PyTorch.
Z niniejszego posta dowiesz się między innymi:
- Jak można podzielić zbiór danych na uczący, walidacyjny i testowy?
- Jak dokonać transformacji zbioru, np. znormalizować dane i co jeżeli potrzebujesz odwrócić proces normalizacji?
- W jaki sposób w PyTorch wykorzystać GPU?
- Jak wyliczać najpopularniejszą metrykę, czyli accuracy, dla pętli uczącej, walidacyjnej i testowej?
Załadowanie i transformacje zbioru
Na początku trochę „formalności”, czyli niezbędne importy z krótkimi wyjaśnieniami w komentarzach dlaczego i po co.
# main librariesimport torchimport torchvision
# All datasets in torchvision.dataset are subclasses# of torch.utils.data.Dataset, thus we may use MNIST directly in DataLoaderfrom torchvision.datasets import CIFAR10from torch.utils.data import DataLoader
# an optimizer and a loss functionfrom torch.optim import Adamfrom torch.nn import CrossEntropyLoss
# required for creating a modelfrom torch.nn import Conv2d, BatchNorm2d, MaxPool2d, Linear, Dropoutimport torch.nn.functional as F
# tools and helpersimport numpy as np from timeit import default_timer as timerimport matplotlib.pyplot as pltfrom torch.utils.data import random_splitfrom torchvision import transformsimport matplotlib.pyplot as plt
Korzystamy z pakietu torchvision, który oferuje klasy do ładowania najpopularniejszych zbiorów danych, na których najprościej eksperymentować. Klasa ładująca zbiór CIFAR10, którą zaraz zastosujemy, jako jeden z parametrów przyjmuje obiekt klasy torchvision.transforms. Umożliwia on wykonanie na ładowanym zbiorze szeregu transformacji takich jak zamiana danych na tensory, normalizacja, dodanie paddingów, wycinanie fragmentów obrazu, obroty, transformacje perspektywy, itp. Przydają się one zarówno w prostych przypadkach, jak i w bardziej skomplikowanych, gdy np. chcemy wykonać data augmentation. Dodatkowo transformacje można serializować, używając torchvision.transforms.Compose.
My potrzebujemy jedynie przekształcić dane do tensora i znormalizować je, stąd:
# Transformations, including normalization based on mean and stdmean = torch.tensor([0.4915, 0.4823, 0.4468])std = torch.tensor([0.2470, 0.2435, 0.2616])transform_train = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean, std)])transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean, std) ])Trzy uwagi do powyższego:
- mean i std to wyliczone wartości średnie oraz ich odchylenie standardowe dla każdego z kanałów obrazka,
- jak widać definiujemy transformatę osobno dla zbioru uczącego i testowego. Są one takie same, bo nie stosujemy dla zbioru uczącego data augmentation. Teoretycznie więc można było zastosować jedną transformatę w obu przypadkach, ale dla jasności, jak również na wypadek gdybyśmy potem chcieli to jednak zmienić, zostawiamy obie transformaty oddzielnie,
- wartości mean i std przydadzą się nam do późniejszej de-normalizacji na potrzeby wyświetlania przykładowych obrazków, bo po normalizacji przestaną one być czytelne dla ludzkiego oka.
Mając transformaty, możemy załadować zbiory. Klasa CIFAR10 jest podklasą torch.utils.data.Dataset, o której szerzej pisałem w tym wpisie.
# Download CIFAR10 dataset dataset = CIFAR10('./', train=True, download=True, transform=transform_train)test_dataset = CIFAR10('./', train=False, download=True, transform=transform_test)dataset_length = len(dataset)print(f'Train and validation dataset size: {dataset_length}')print(f'Test dataset size: {len(test_dataset)}')>>>Train and validation dataset size: 50000>>>Test dataset size: 10000# The output of torchvision datasets are PILImage images of range [0, 1]. # but they have been normalized and converted to tensorsdataset[0][0][0]>>> tensor([>>> [-1.0531, -1.3072, -1.1960, ..., 0.5187, 0.4234, 0.3599],>>> [-1.7358, -1.9899, -1.7041, ..., -0.0370, -0.1005, -0.0529],>>> [-1.5930, -1.7358, -1.2119, ..., -0.1164, -0.0847, -0.2593],>>> ...,>>> [ 1.3125, 1.2014, 1.1537, ..., 0.5504, -1.1008, -1.1484],>>> [ 0.8679, 0.7568, 0.9632, ..., 0.9315, -0.4498, -0.6721],>>> [ 0.8203, 0.6774, 0.8521, ..., 1.4395, 0.4075, -0.0370]])Denormalizacja i wyświetlenie
Dobrą praktyką jest podejrzenie przykładowych elementów ze zbioru uczącego. Problemem jest jednak to, że zostały one znormalizowane, czyli wartości poszczególnych pikseli zostały zmienione oraz przekształcone do tensora, co z kolei zmieniło kolejność kanałów obrazka. Poniżej klasa de-normalizująca i przywracająca pierwotny kształt.
# Helper callable class that will un-normalize image and# change the order of tensor elements to display image using pyplot.class Detransform(): def __init__(self, mean, std): self.mean = mean self.std = std # PIL images loaded into dataset are normalized. # In order to display them correctly we need to un-normalize them first def un_normalize_image(self, image): un_normalize = transforms.Normalize( (-self.mean / self.std).tolist(), (1.0 / self.std).tolist() ) return un_normalize(image) # If 'ToTensor' transormation was applied then the PIL images have CHW format. # To show them using pyplot.imshow(), we need to change it to HWC with # permute() function. def reshape(self, image): return image.permute(1,2,0)
def __call__(self, image): return self.reshape(self.un_normalize_image(image))# Create detransformer to be used whil printing imagesdetransformer = Detransform(mean, std)Potrzebujemy jeszcze słownika, który tłumaczyłby numery klas na ich nazwy, zgodnie z definicją zbioru CIFAR10, a także funkcji wyświetlającej kilka losowo wybranych obrazków.
# Translation between class id and nameclass_translator = { 0 : 'airplane', 1 : 'automobile', 2 : 'bird', 3 : 'cat', 4 : 'deer', 5 : 'dog', 6 : 'frog', 7 : 'horse', 8 : 'ship', 9 : 'truck',}# Helper function printing 9 randomly selected pictures from the datasetdef print_images(): fig = plt.figure() fig.set_size_inches(fig.get_size_inches() * 2) for i in range(9): idx = torch.randint(0, 50000, (1,)).item() picture = detransformer(dataset[idx][0]) ax = plt.subplot(3, 3, i + 1) ax.set_title(class_translator[dataset[idx][1]] + ' - #' + str(idx)) ax.axis('off') plt.imshow(picture) plt.show()No to przyjrzymy się kilku elementom tego zbioru …
print(f'The first element of the dataset is a {class_translator[dataset[0][1]]}.')>>>The first element of the dataset is a frog.image = detransformer(dataset[0][0])plt.imshow(image)
print_images()
Podział zbioru na uczący, testowy i walidacyjny
Należy zauważyć, że konstruktor zbioru CIFAR10 umożliwia pobranie albo zbioru uczącego, albo testowego. Co jednak, jeśli chcemy wydzielić jeszcze zbiór walidacyjny, który pozwoli nam określić skuteczność w trakcie uczenia? Musimy samodzielnie wydzielić go z ze zbioru uczącego. Pomocna w tym zakresie będzie funkcja random_split z pakietu torch.utils.data.
validation_length = 5000# Split training dataset between actual train and validation datasetstrain_dataset, validation_dataset = random_split(dataset, [(dataset_length - validation_length), validation_length])Mając trzy obiekty klasy Dataset: train_dataset, validation_dataset i test_dataset możemy zdefiniować DataLoadery, które umożliwią serwowanie danych w batchach.
# Create DataLoaderstrain_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)validation_dataloader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False)test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# Print some statisticsprint(f'Batch size: {batch_size} data points')print(f'Train dataset (# of batches): {len(train_dataloader)}')print(f'Validation dataset (# of batches): {len(validation_dataloader)}')print(f'Test dataset (# of batches): {len(test_dataloader)}')>>> Batch size: 256 data points>>> Train dataset (# of batches): 176>>> Validation dataset (# of batches): 20>>> Test dataset (# of batches): 40Architektura modelu
Aby nie skupiać się zbytnio na architekturze sieci, którą chcemy zastosować – bo nie taki jest cel niniejszego posta – wykorzystamy sieć zaprojektowaną w tym wpisie na temat konwolucyjnych sieci neuronowych. Warto jednak w tym miejscu zauważyć, że jednym z zagadnień przy projektowaniu sieci jest wymiarowanie danych. Aby sprawdzić wielkość wektora wejściowego, jaki będzie serwowany przez DataLoader, można wykonać następujący kod:
# Before CNN definition, let's check the sizing of input tensordata, label = next(iter(train_dataloader))print(data.size())print(label.size())>>> torch.Size([256, 3, 32, 32])>>> torch.Size([256])Mamy tu zatem batch wielkości 256, następnie trzy kanały RBG obrazka, każdy o wielkości 32 na 32.
W wymiarowaniu sieci konwolucyjnej pomóc może ten skrypt. Oczywiście wymaga on rozbudowania / dostosowania do potrzeb danego modelu.
Ostatecznie nasza architektura będzie wyglądała następująco:
class CifarNN(torch.nn.Module): def __init__(self): super().__init__() self.conv1 = Conv2d(3, 128, kernel_size=(5,5), stride=1, padding='same') # [B, 128, 32, 32] self.bnorm1 = BatchNorm2d(128) self.conv2 = Conv2d(128, 128, kernel_size=(5,5), stride=1, padding='same') # [B, 128, 32, 32] self.bnorm2 = BatchNorm2d(128) self.pool1 = MaxPool2d((2,2)) # [B, 128, 16, 16] self.conv3 = Conv2d(128, 64, kernel_size=(5,5), stride=1, padding='same') # [B, 64, 16, 16] self.bnorm3 = BatchNorm2d(64) self.conv4 = Conv2d(64, 64, kernel_size=(5,5), stride=1, padding='same') # [B, 64, 16, 16] self.bnorm4 = BatchNorm2d(64) self.pool2 = MaxPool2d((2,2)) # [B, 64, 8, 8] self.conv5 = Conv2d(64, 32, kernel_size=(5,5), stride=1, padding='same') # [B, 32, 8, 8] self.bnorm5 = BatchNorm2d(32) self.conv6 = Conv2d(32, 32, kernel_size=(5,5), stride=1, padding='same') # [B, 32, 8, 8] self.bnorm6 = BatchNorm2d(32) self.pool3 = MaxPool2d((2,2)) # [B, 32, 4, 4] self.conv7 = Conv2d(32, 16, kernel_size=(3,3), stride=1, padding='same') # [B, 16, 4, 4] self.bnorm7 = BatchNorm2d(16) self.conv8 = Conv2d(16, 16, kernel_size=(3,3), stride=1, padding='same') # [B, 16, 4, 4] self.bnorm8 = BatchNorm2d(16) self.linear1 = Linear(16*4*4, 32) self.drop1 = Dropout(0.15) self.linear2 = Linear(32, 16) self.drop2 = Dropout(0.05) self.linear3 = Linear(16, 10) def forward(self, x): # the first conv group x = self.bnorm1(self.conv1(x)) x = self.bnorm2(self.conv2(x)) x = self.pool1(x) # the second conv group x = self.bnorm3(self.conv3(x)) x = self.bnorm4(self.conv4(x)) x = self.pool2(x) # the third conv group x = self.bnorm5(self.conv5(x)) x = self.bnorm6(self.conv6(x)) x = self.pool3(x) # the fourth conv group (no maxpooling at the end) x = self.bnorm7(self.conv7(x)) x = self.bnorm8(self.conv8(x)) # flatten x = x.reshape( -1, 16*4*4) # the first linear layer with ReLU x = self.linear1(x) x = F.relu(x) # the first dropout x = self.drop1(x) # the second linear layer with ReLU x = self.linear2(x) x = F.relu(x) # the second dropout x = self.drop2(x) # the output layer logits (10 neurons) x = self.linear3(x) return x
Przenosimy się na GPU i wyliczamy accuracy
Uczenie nieco bardziej rozbudowanej sieci neuronowej na CPU nie ma większego sensu. Prosty test jaki przeprowadziłem na Google Colab pokazał, że przejście jednej epoki na CPU zajmuje około 2600 sekund, gdy tymczasem na GPU to samo zajęło 66 sekund. Te czasy w oczywisty sposób zależą od wielu czynników, na które nie mamy wpływu, jak choćby na jakie maszyny skieruje nas silnik Google Colab, ale wnioski zawsze będą podobne – uczenie na GPU może być kilkadziesiąt razy szybsze.
Jak zatem najprościej przesiąść się w PyTorch z CPU na GPU? Oczywiście w Google Colab musimy wykonać Runtime->Change runtime type i zmienić środowisko wykonawcze na GPU. Ale główne zmiany należy wykonać w kodzie. Na szczęście nie ma ich dużo i są one dość proste.
Sprawa zasadnicza to ustalenie z jakim środowiskiem mamy do czynienia. Poniższy fragment kodu jest powszechnie stosowaną dobrą praktyką.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(device)>>> cudaW następnym kroku tworzymy model i przenosimy go na aktualnie dostępne urządzenie.
model = CifarNN()model = model.to(device)Każde uczenie musi mieć zdefiniowane kilka parametrów oraz wskazanie użytych narzędzi. Poniżej określamy ilość epok, learning_rate oraz optimizer, jak również sposób liczenia błędu. Pojawiają się również po raz pierwszy dwie listy, w których w każdej epoce będziemy zapisywali accuracy. Umożliwi to nam potem narysowanie ładnego wykresu.
epochs = 40learning_rate = 0.001train_accuracies = [] # cummulated accuracies from training dataset for each epochval_accuracies = [] # cummulated accuracies from validation dataset for each epochoptimizer = Adam( model.parameters(), lr=learning_rate)criterion = CrossEntropyLoss()Poniższy kod to główna pętla ucząca. Dzieje się tu kilka rzeczy, które nas mogą interesować w kontekście niniejszego posta, więc do niektórych linii przypisałem indeksy, które krótko skomentuję:
(1) – będziemy mierzyli czas uczenia.
(2) – dobrą praktyką jest sygnalizowanie silnikowi PyTorch kiedy następuje uczenie, a kiedy jedynie ewaluacja na zbiorze walidacyjnym lub testowym. Istotnie poprawia to wydajność części ewaluacyjnych.
(3) – przenosimy dane (batch) na GPU.
(4) – wartość, którą otrzymujemy po przepuszczeniu danej wejściowej przez sieć (tu: yhat) to tzw. logits, czyli wartości teoretycznie z przedziału od plus do minus nieskończoności. Target zawiera liczby od 0 do 9 wskazujące na właściwą klasę. Funkcja obliczająca błąd sieci (tu: CrossEntropyLoss) wewnętrznie radzi sobie z odpowiednim porównaniem tych wartości. My jednak obliczając accuracy – w punkcie (5) – musimy najpierw samodzielnie obliczyć odpowiedź sieci. Używamy do tego funkcji argmax, która zwraca indeks, w którym występuje najsilniejsza (największa co do wartości) odpowiedź sieci. Indeks ten będzie jednocześnie numerem klasy, do której sieć przypisała wartość wejściową. W ten sposób otrzymujemy prediction – wektor zawierający przypisanie klasy dla każdego elementu aktualnie przetwarzanego batcha.
(5) – do wyliczenia accuracy bazującej na danych w dwóch wektorach y i prediction najwygodniej użyć biblioteki numpy, która świetnie radzi sobie z wektoryzacją operacji. Aby dane, które znajdują się na GPU trafiły ostatecznie do listy przetwarzanej w środowisku CPU musimy użyć .detach().cpu().numpy().
(6) – dla każdej epoki uczenia przetwarzamy zbiór walidacyjny i wyliczamy dla niego accuracy, aby porównać z accuracy wyliczoną dla zbioru uczącego. Na tej podstawie będziemy widzieli czy proces uczenia wpadł w overfitting czy nie.
start = timer() # (1)for epoch in range(epochs): model.train() # (2) train_accuracy = [] for x, y in train_dataloader: x = x.to(device) # (3) y = y.to(device) # (3) optimizer.zero_grad() yhat = model.forward(x) loss = criterion(yhat, y) loss.backward() optimizer.step() prediction = torch.argmax(yhat, dim=1) # (4) train_accuracy.extend((y == prediction).detach().cpu().numpy()) # (5) train_accuracies.append(np.mean(train_accuracy)*100) # for every epoch we do a validation step to asses accuracy and overfitting model.eval() # (2) with torch.no_grad(): # (2) val_accuracy = [] # accuracies for each batch of validation dataset for vx, vy in validation_dataloader: (6) vx = vx.to(device) # (3) vy = vy.to(device) # (3) yhat = model.forward(vx) prediction = torch.argmax(yhat, dim=1) (4) # to numpy in order to use next the vectorized np.mean val_accuracy.extend((vy == prediction).detach().cpu().numpy()) (5) val_accuracies.append(np.mean(val_accuracy)*100) # simple logging during training print(f'Epoch #{epoch+1}. Train accuracy: {np.mean(train_accuracy)*100:.2f}. \ Validation accuracy: {np.mean(val_accuracy)*100:.2f}') end = timer() # (1)W efekcie uczenia na 40 epokach otrzymujemy następujące wyniki:
>>> Epoch #1. Train accuracy: 34.20. Validation accuracy: 47.32>>> Epoch #2. Train accuracy: 51.58. Validation accuracy: 57.00>>> Epoch #3. Train accuracy: 58.11. Validation accuracy: 61.56>>> Epoch #4. Train accuracy: 62.18. Validation accuracy: 64.16................................................................>>> Epoch #38. Train accuracy: 90.86. Validation accuracy: 73.86>>> Epoch #39. Train accuracy: 91.42. Validation accuracy: 73.30>>> Epoch #40. Train accuracy: 91.68. Validation accuracy: 73.40
Jak widać różnica między accuracy na zbiorze uczącym (91%) a zbiorze walidacyjnym (73%) jest spora. Model wpadł w overfitting, co bardzo dobrze pokazuje zresztą poniższy wykres.
print(f'Processing time on a GPU: {end-start:.2f}s.') >>> Processing time on a GPU: 3113.36s.plt.plot(train_accuracies, label="Train accuracy")plt.plot(val_accuracies, label="Validation accuracy")leg = plt.legend(loc='lower right')plt.show()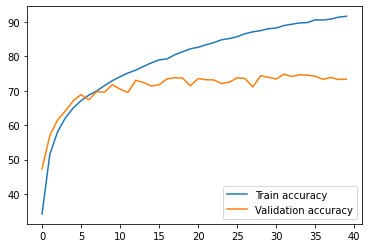
Problem overfittingu jest istotny i jest kilka metod, które można zastosować, aby go zmniejszyć. Część została zresztą zaaplikowana do powyższego modelu (np. warstwa Dropout). Więcej o zapobieganiu overfittingowi w tym poście.
Na koniec procesu uczenia sprawdzamy jak model radzi sobie na zbiorze testowym, czyli danych, których model nie widział podczas uczenia.
# calculate accuracy on the test dataset that the model has never seen beforemodel.eval()with torch.no_grad(): test_accuracies = [] for x, y in test_dataloader: x = x.to(device) y = y.to(device) yhat = model.forward(x) prediction = torch.argmax(yhat, dim=1) test_accuracies.extend((prediction == y).detach().cpu().numpy()) # we store accuracy using numpy test_accuracy = np.mean(test_accuracies)*100 # to easily compute mean on boolean valuesprint(f'Accuracy on the test set: {test_accuracy:.2f}%') >>>Accuracy on the test set: 72.78%
Podsumowanie
Niniejszy post miał charakter narzędziowy. Skupiliśmy się na kilku obszarach, które są czasami trudniejsze technicznie niż sam proces budowania architektury modelu. Zobaczyliśmy w jaki sposób można załadować zbiór i podzielić go na trzy podzbiory: uczący, walidacyjny i testowy. Pobieżnie przyjrzeliśmy się transformacjom jakich można dokonywać korzystając z klasy transforms oraz w jaki sposób można wyświetlić obrazki ze zbioru uczącego, odwracając uprzednio transformację. Po krótkim przystanku przy wymiarowaniu sieci nasza uwaga przeniosła się na uczenie w środowisku GPU oraz wyliczenie accuracy. Uzyskany efekt: 72% trafności na zbiorze testowym to nie jest zbyt dobry wynik dla zbioru CIFAR10, ale nie to było celem posta. Osobom zainteresowanym podniesieniem efektywności uczenia polecam post dotyczący data augmentation. Wprawdzie wykorzystuje on framework Keras, ale PyTorch również oferuje narzędzia do wykonania analogicznych operacji. Bardziej zresztą istotna jest sama idea stojąca za serwowaniem do uczenia sztucznie modyfikowanych danych niż użyta biblioteka.
Całość skryptu dostępna w moim repo na githubie.