

Przygotowanie danych do uczenia maszynowego nie jest zadaniem, za którym tęskni większość specjalistów AI. Dane bywają różnej jakości, najczęściej wymagają bardzo dokładnej analizy, czasami ręcznego przeglądu, a na pewno selekcji i wstępnego przetworzenia. W przypadku zadań klasyfikacyjnych podział zbioru na klasy bywa niewłaściwy lub niewystarczająco zbalansowany. Często danych jest również po prostu za mało i trzeba je sztucznie wygenerować. Jednym zdaniem: łatwo nie jest. Niemniej, jest to niezbędny krok i kto wie czy nie ważniejszy niż późniejszy tuning algorytmu uczącego. Częścią etapu przygotowania danych jest ich pobranie z uprzednio przygotowanego zbioru i możliwość serwowania (najczęściej w paczkach) do algorytmu uczącego. W niniejszym wpisie chciałbym przyjrzeć się metodom serwowania danych, jakie oferuje biblioteka PyTorch.
Z niniejszego posta dowiesz się między innymi:
- Jak przygotować środowisko conda do pracy z Pytorch?
- Do czego służą klasy Dataset i DataLoader?
- Jak użyć ich do pracy z jednym z predefiniowanych zbiorów danych udostępnianych przez bibliotekę PyTorch?
- Jak użyć Dataset i DataLoader do zaimportowania własnego zbioru danych?
- Jak można pobierać danych do uczenia maszynowego ze zbioru danych składającego z wielu oddzielnych plików, np. plików graficznych leżących na dysku?
Ale najpierw przygotujmy środowisko…
Poniżej załączam krótką instrukcję przygotowania środowiska dla PyTorch. Dzięki temu będzie prościej samodzielnie odtworzyć metody zaprezentowane poniżej. Oczywiście, jeżeli masz już gotowe środowisko możesz pominąć ten fragment posta.
Korzystam z condy i na lokalnym środowisku nie mam karty zgodnej z CUDA, więc potrzebuję kompilacji dla CPU. Na początek zawsze warto sprawdzić aktualność wersji condy:
> conda -V> conda update -n base -c defaults conda
Następnie tworzymy środowisko pod nasze prace, aktywujemy i instalujemy niezbędne pakiety. Zwróć uwagę na cpuonly – jeżeli masz CUDA, to instalacja nie powinna obejmować tego parametru. Istotny może być również parametr -c pytorch, wskazujący dedykowany kanał, w którym znajdą się odpowiednie wersje pytorch i torchvision.
> conda create --name pytorch_env> conda activate my_env> conda install jupyter pytorch torchvision numpy matplotlib cpuonly -c pytorch
Na koniec przechodzimy do katalogu roboczego, w którym zamierzamy zapisywać skrypty, uruchamiamy Jupyter Notebook i wykonujemy prosty test.
> cd <<my working directory>>> jupyter notebook
import torchx = torch.rand(5, 3)print(x)>>> tensor([[0.3425, 0.0880, 0.5301], [0.5414, 0.2990, 0.5740], [0.3530, 0.0147, 0.5289], [0.2170, 0.3744, 0.7805], [0.6985, 0.5344, 0.7144]])
Jeżeli przy wykonywaniu powyższego napotkasz na jakiekolwiek problemy, nie masz zainstalowanej Anacondy lub możesz / chcesz używać CUDA, to odsyłam do tej instrukcji.
Przygotowanie danych – scenariusz najprostszy.
PyTorch daje możliwość skorzystania z dwóch klas do obróbki danych: torch.utils.data.Dataset oraz torch.utils.data.DataLoader. Nieco upraszczając, zadaniem Dataset jest pobranie ze zbioru pojedynczej danej wraz z jej opisem (label), natomiast DataLoader otacza dane pobrane przez Dataset iteratorem, zapewnia serwowanie ich w batchach, działanie w wielu wątkach, aby przyspieszyć pobieranie danych do uczenia, jak również takie operacje jak choćby mieszanie danych.
PyTorch udostępnia również wiele przykładowych zbiorów, na których dość prosto można przeprowadzić testy pobierania danych i uczenia. I od takiego scenariusza rozpoczniemy, przygotowując dane do uczenia na znanym nam już zbiorze MNIST. Poniżej importujemy bibliotekę torch, Dataset oraz pakiet torchvision.datasets zawierający wiele przykładowych zbiorów z obszaru rozpoznawania obrazów. Każdy zbiór danych jest podklasą Dataset co oznacza, że zaimplementowano za nas metody _getitem__ oraz __len__, o czym więcej nieco później.
import torchfrom torch.utils.data import Datasetfrom torchvision import datasets
Kiedy importujemy dane z dowolnego zbioru, najczęściej potrzebujemy je w pewien sposób przekształcić (np. znormalizować). Pakiet torchvision, jak również inne pakiety z przykładowymi zbiorami danych dostępne w PyTorch, posiadają zdefiniowane transformaty dostępne w pakiecie transforms. W naszym przykładzie skorzystamy z jednej z nich, która konwertuje daną pobraną ze zbioru do tensora PyTorch.
from torchvision.transforms import ToTensorimport matplotlib.pyplot as plt
Samo pobranie zbioru jest bardzo proste: tworzymy obiekt klasy danego zbioru (w naszym przykładzie MNIST) przekazując kilka parametrów, tu katalog lokalny, do którego ściągnięte zostaną dane, wskazanie czy pobieramy zbiór uczący czy testowy, aplikowane transformaty – a możemy podać ich kilka – oraz flagę czy zbiór pobrać na dysk, tak aby nie było konieczności pobierania go za każdym razem.
training_dataset = datasets.MNIST(root='mnistdata', train=True, transform=ToTensor(), download=True)
Dalsze korzystanie ze zbioru sprowadza się do wywołania obiektu, który zwróci parę (tuple): dana i label:
image, label = training_dataset[100]print(type(image))print(image.size())print(type(label))
>>> <class 'torch.Tensor'>>>> torch.Size([1, 28, 28])>>> <class 'int'>
Pobrany obrazek możemy wyświetlić:
plt.imshow(image.squeeze())plt.title(label)plt.show()
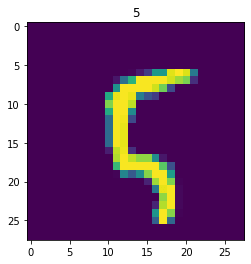
Teraz na scenę może wkroczyć klasa DataLoader i wykorzystując utworzony obiekt klasy Dataset możemy opakować go w dodatkowe funkcje przydatne do uczenia maszynowego:
from torch.utils.data import DataLoaderdataloader = DataLoader( dataset=training_dataset, batch_size=5)
Po tak utworzonym DataLoaderze możemy swobodnie iterować, a każda iteracja dostarczy nam odpowiednią ilość danych – w naszym przypadku batch o wielkości 5:
images, labels = next(iter(dataloader))print(type(images), type(labels))print(images.size(), labels.size())
>>> <class 'torch.Tensor'> <class 'torch.Tensor'>>>> torch.Size([5, 1, 28, 28]) torch.Size([5])
Załóżmy, że chcemy wyświetlić zawartość drugiego obrazka w tak pobranym batchu:
idx = 2label = labels[idx].item()image = images[idx]plt.imshow(image.squeeze())plt.title(label)plt.show()
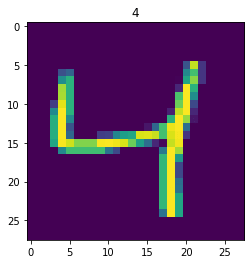
Teraz wystarczy wykorzystać wytworzone struktury danych w procesie uczenia. O tym jak to zrobić zajmiemy się w innym poście, a teraz zobaczmy jak możemy wykorzystać Dataset i DataLoader w bardziej życiowych sytuacjach.
Jak wykorzystać własny Dataset?
Bardziej życiową sytuacją będzie na pewno wykorzystanie własnego zbioru danych, a nie przykładowego zbioru osadzonego w pakiecie PyTorch. Dla uproszczenia przyjmijmy, że naszym zbiorem danych będzie 500 odczytów 10 liczb całkowitych, wraz z ich klasyfikacją na 10 klas, oznaczonych cyframi od 0 do 9.
Pierwszym krokiem w procesie przygotowania własnego zbioru danych jest zdefiniowanie naszej własnej klasy, ale dziedziczącej po omawianej powyżej „abstrakcyjnej” klasie Dataset. Implementacja jest o tyle prosta, że klasa taka wymaga nadpisania jedynie dwóch metod, o których pisałem powyżej: __getitem__ i __len__. Plus oczywiście należy zapewnić kod metody inicjującej obiekt __init__. Ponieważ nasz zbiór będzie randomowo generowany, to konstruktor będzie przyjmował 4 parametry: początek i koniec przedziału liczb całkowitych dla generatora liczb oraz wielkość zbioru, tu 500 wierszy po 10 wartości każdy. W konstruktorze inicjujemy również labelki – także losowo. Całościowo kod przedstawia się następująco:
import torchfrom torch.utils.data import Dataset, DataLoader
class RandomIntDataset(Dataset): def __init__(self, start, stop, x, y): # losowo generujemy tablicę intów, które będą pełniły funkcję danych self.data = torch.randint(start, stop, (x,y)) # losowo generujemy wektor intów, pełniących rolę labelek self.labels = torch.randint(0, 10, (x,))
def __len__(self): # wielkość zbioru równa jest długości wektora return len(self.labels)
def __str__(self): # łączymy obie struktury danych, aby zaprezentować je w formie jednej tabeli return str(torch.cat((self.data, self.labels.unsqueeze(1)), 1))
def __getitem__(self, i): # metoda zwraca zwraca parę: dana - labelka dla indeksu o numerze i return self.data[i], self.labels[i]
W kolejnym kroku tworzymy obiekt klasy RandomIntDataset podając odpowiednie parametry i sprawdzamy wielkość wygenerowanego zbioru:
dataset = RandomIntDataset(100, 1000, 500, 10)len(dataset)>>> 500
Zobaczmy jak wygląda nasz nowo utworzony zbiór – w ostatniej kolumnie widoczna jest klasa pojedynczej próbki danych:
print(dataset)>>> tensor([[627, 160, 881, ..., 485, 457, 9], [705, 511, 947, ..., 744, 465, 5], [692, 427, 701, ..., 639, 378, 9], ..., [601, 228, 749, ..., 155, 823, 4], [599, 627, 802, ..., 179, 693, 4], [740, 861, 697, ..., 286, 160, 4]])
Tak przygotowany obiekt możemy wykorzystać otaczając go, jak w poprzednim przykładzie, DataLoaderem, a następnie w dość prosty sposób iterować po batchach zbioru – w naszym przypadku 4-elementowych.
dataset_loader = DataLoader(dataset, batch_size=4, shuffle=True)data, labels = next(iter(dataset_loader))data>>> tensor([[724, 232, 501, 555, 369, 142, 504, 226, 849, 924], [170, 510, 711, 502, 641, 458, 378, 927, 324, 701], [838, 482, 299, 379, 181, 394, 473, 739, 888, 265], [945, 421, 983, 531, 237, 106, 261, 399, 161, 459]])labels>>> tensor([3, 6, 9, 7])
Pobieranie danych z plików
W zadaniach z obszaru computer vision często spotykamy się sytuacją, w której dane (obrazy, filmy, anotacje) są zapisane w postaci danych / plików na dysku. Dziedziczenie po klasie abstrakcyjnej Dataset i nadpisanie jej metod da nam możliwość zrealizowania pobierania takich plików wg schematu bliźniaczego do opisanego powyżej:
- tworzymy klasę dziedziczącą po Dataset,
- definiujemy metody __init__, __getitem__ oraz __len__, plus ewentualne inne pomocnicze metody,
- tworzymy obiekt tej klasy i przekazujemy go do DataLoadera.
Przyjrzyjmy się teraz, w jaki sposób można zaimplementować pobieranie danych dla zbioru Facial Key Point Detection Dataset. Po pobraniu i rozpakowaniu pliku otrzymamy katalog images zawierający 5000 plików graficznych, dociętych do tego samego rozmiaru oraz plik w formacie json zawierający koordynaty 68 kluczowych punktów twarzy dla każdego z plików. Te kluczowe punkty z reguły identyfikują oczy, linię ust, brwi oraz owal twarzy.
Zbiór został przygotowany przez Prashant Arora jako podzbiór oryginalnego, dużo większego zbioru danych Flickr-Faces-HQ, stworzonego przez zespół NVIDIA i udostępnionego z wykorzystaniem licencji Creative Commons BY-NC-SA 4.0.
Importujemy niezbędne biblioteki i tworzymy klasę dziedziczącą po Dataset, w której implementujemy trzy wymagane metody. Metoda __init__ ustawia zmienną wskazującą na nazwę katalogu z danymi. Powinien on znajdować się w katalogu, z którego uruchamiamy niniejszy skrypt. Do katalogu z danymi powinniśmy uprzednio wypakować pobrany zbiór. Metoda __len__ zwraca wielkość zmiennej z koordynatami kluczowych punktów, która jest jest jednocześnie wielkością całego zbioru. Metoda __getitem__ w pierwszej kolejności pobiera nazwę pliku o indeksie i ze zmiennej z koordynatami, a następnie wczytuje obraz z odpowiedniego pliku z katalogu images.
import torchfrom torch.utils.data import Dataset, DataLoaderimport json # we need to import json file with key points coordinatesimport numpy as npimport matplotlib.image as imgimport matplotlib.pyplot as plt
class FacialDetection(Dataset): def __init__(self, dataset_directory="FacialKeyPoint"): # set root directory for your dataset self.dataset_directory = dataset_directory
# read json file with annotations annotations_file = open(self.dataset_directory + "\\all_data.json") self.annotations = json.load(annotations_file)
def __len__(self): return len(self.annotations)
def __getitem__(self, i): image_filename = self.annotations[str(i)]['file_name'] image_path = self.dataset_directory + "\\images\\" + image_filename image = img.imread(image_path)
points = self.annotations[str(i)]['face_landmarks']
return image, np.array(points)
Możemy teraz utworzyć obiekt naszej nowej klasy i sprawdzić czy na pewno dysponujemy zbiorem o 5000 elementów:
dataset = FacialDetection()len(dataset)>>> 5000
Pobierzmy jeden z obrazków, np. o indeksie 888 i wyświetlmy zawartość:
image, key_points = dataset.__getitem__(888)plt.imshow(image)plt.show()

I ten sam obrazek z naniesionymi punktami kluczowymi:
plt.imshow(image)plt.scatter(key_points[:, 0], key_points[:, 1], marker='o', c='y', s=5)plt.show()

Gdybyśmy chcieli serwować ten zbiór do uczenia maszynowego, wystarczy go jak uprzednio otoczyć klasą DataLoader i iterować po zwróconym obiekcie.
dataset_loader = DataLoader(dataset, batch_size=4, shuffle=True)data, labels = next(iter(dataset_loader))data.size()>>> torch.Size([4, 512, 512, 3])
labels.size()>>> torch.Size([4, 68, 2])
Krótkie podsumowanie
Klasy Dataset i DataLoader oferują prosty i co ważne standaryzowany sposób dostępu do danych i ich dalszego przetwarzania w uczeniu maszynowym. Poza samym faktem standaryzacji, który mocno upraszcza programowanie w wielu zastosowaniach, klasy te są również wykorzystywane do łatwego dostępu do zbiorów danych udostępnianych w bibliotece Pytorch, a dotyczących rozpoznawania obrazu, pracy z dźwiękiem i tekstem. Co ważne torchvision, torchtext i torchaudio dają możliwość skorzystania z predefiniowanych transformat (tu przykład dla torchvision) i użycia ich w DataLoaderze. Można również skorzystać z tych transformat we własnej klasie lub napisać swoją transformatę. Tematu tego nie poruszyłem w powyższym wpisie, ale warto go zasygnalizować, jako dodatkową zaletę. Jeszcze inną korzyścią z wykorzystania ww. klas jest możliwość sparametryzowania przetwarzania równoległego na wielu CPU, na GPU oraz optymalizacji transferu danych między CPU a GPU, co ma znaczenie przy przetwarzaniu bardzo dużych ilości danych.