

Computer Vision jest jednym z najciekawszych i moim ulubionym obszarem zastosowań dla sztucznej inteligencji. Sporym wyzwaniem dla algorytmów analizy obrazów jest szybka detekcja i klasyfikacja obiektów w czasie rzeczywistym. Problem detekcji obiektów jest dużo trudniejszy niż klasyfikacja, którą wielokrotnie omawiałem na moim blogu, ponieważ nie tylko musimy wskazać co to za obiekt, ale również miejsce, w którym się on znajduje. Można prosto wymienić dziesiątki zastosowań dla algorytmów detekcji, ale uogólniając można założyć, że maszyna (np. autonomiczny samochód, robot przemysłowy, system detekcji / oceny) powinna być w stanie w czasie rzeczywistym identyfikować widoczne obiekty (ludzi, oznakowanie, obiekty przemysłowe, inne maszyny, itp.), aby dostosowywać swoje kolejne zachowania lub wysyłane sygnały do sytuacji zastanej w otoczeniu. I tu na scenę wchodzi You Only Look Once (YOLO).
YOLO został zaproponowany przez Josepha Redmona et al., a jego najnowsza, na dzień pisania tego posta, wersja trzecia jest opisana w pracy YOLOv3: An Incremental Improvement. Polecam również poniższe nagranie wystąpienia Redmona na TEDx.
Trzema najważniejszymi cechami algorytmu YOLO, które wyróżniają go na tle konkurencji są:
- Użycie grida zamiast pojedynczego okna przesuwającego się po obrazku (jak to ma miejsce np. w Fast R-CNN). Dzięki takiemu podejściu sieć neuronowa widzi od razu cały obrazek a nie tylko jego niewielką część. Dzięki temu może nie tylko przeanalizować cały obraz szybciej, ale również wyciągać wnioski z całej zawartości informacyjnej obrazu, a nie tylko z jego wycinka, który nie zawsze niesie ze sobą informacje kontekstowe. Dzięki tej ostatniej cesze, YOLO generuje dużo mniej pomyłek polegających na wzięciu fragmentu tła za obiekt – jeden z głównych problemów konkurencyjnego algorytmu Fast R-CNN.
- Sprowadzenie problemu klasyfikacji i lokalizacji obiektu do jednego problemu klasy regresji, kiedy to wektor wyjściowy zawiera zarówno prawdopodobieństwa klas, jak i koordynaty obszaru zawierającego obiekt (tzw. bounding box).
- Bardzo skuteczna generalizacja wiedzy. Jako ciekawostkę potwierdzającą tę cechę autorzy wykazują, że YOLO wyuczone na obrazach przedstawiających naturę, doskonale radzi sobie w detekcji obiektów na dziełach sztuki.
W efekcie otrzymujemy algorytm, który nie tylko jest w stanie przetworzyć ponad 45 klatek na sekundę, ale również daje zbliżoną (choć nieco niższą) skuteczność detekcji do zdecydowanie wolniejszych rozwiązań.
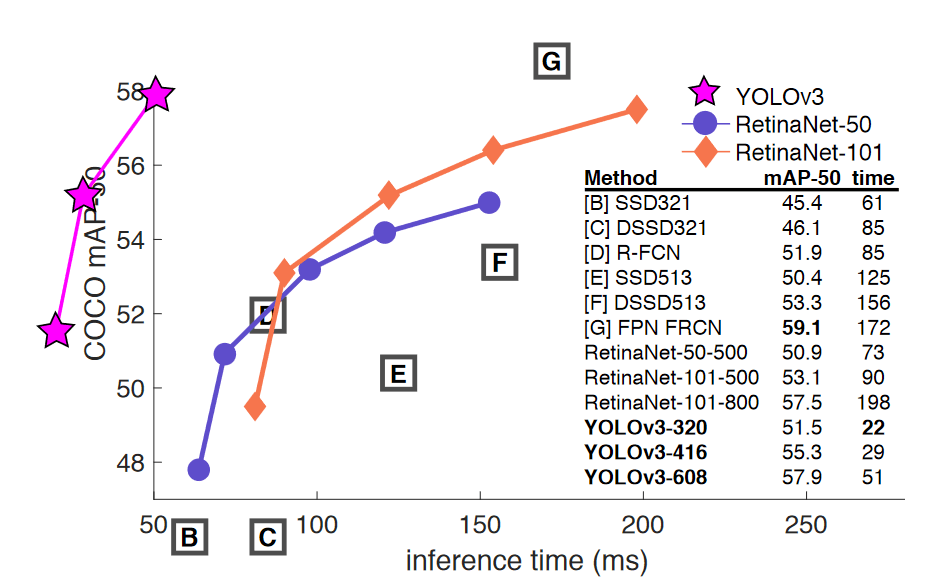
YOLO szybka detekcja i klasyfikacja obiektów – jak to działa?
Tradycyjne metody detekcji obiektów najczęściej dzielą cały proces na kilka etapów. Dla przykładu Faster R-CNN najpierw wykorzystuje konwolucyjną sieć neuronową aby wydobyć poszukiwane cechy obrazka (tzw. feature extraction). Następnie wynik w postaci wyjściowego feature map jest wejściem do kolejnej sieci neuronowej, której zadaniem jest zaproponowanie regionów obrazka, w których mogą znajdować się obiekty. Taka sieć nosi nazwę Region Proposal Network (RPN) i jest ona zarówno klasyfikatorem (wskazuje prawdopodobieństwo, że dany region zawiera obiekt), jak i modelem regresyjnym (opisuje region obrazka zawierający potencjalny obiekt). Wynik działania RPN jest przekazywany do trzeciej sieci neuronowej, której zadaniem jest przewidzenie klasy obiektu i prostokąta otaczającego (bounding box). Jak widać jest to dość skomplikowany, wieloetapowy proces, który niejako z założenia musi trwać dość długo, przynajmniej w porównaniu do YOLO.
YOLO przyjmuje zupełnie inne podejście. Przede wszystkim traktuje zagadnienie detekcji jak pojedynczy problem regresji. Nie dzieli analizy na etapy. Zamiast tego pojedyncza konwolucyjna sieć neuronowa jednocześnie przewiduje wiele obszarów, w których powinien znajdować się obiekt (bounding boxes) oraz wyznacza prawdopodobieństwa klas dla każdego z obszarów, w których obiekt został wykryty.
W pierwszym kroku YOLO nakłada na obraz siatkę o rozmiarach S x S. Na przykład dla S=4 otrzymamy 16 komórek, jak na obrazku poniżej.

Dla każdej komórki YOLO przewiduję B obiektów. B z reguły jest niewielką liczbą, np. 2. Oznacza to, że zakładamy, iż w każdej komórce YOLO zidentyfikuje co najwyżej 2 obiekty. Oczywiście na obrazie może być więcej nakładających się na siebie obiektów. Ale w sytuacji, gdy w danej komórce są 3 lub więcej nachodzących na siebie obiektów, to stają się one bardzo trudne do identyfikacji – szczególnie, jeżeli weźmiemy pod uwagę fakt, że S z reguły jest większe niż użyte w naszym przykładzie 4 i co za tym idzie nakładana siatka ma większą granulację.
Tak więc dla każdej komórki grida YOLO przewiduje czy znajdują się w nim obiekty i dla każdego z nich określane są koordynaty prostokąta otaczającego obiekt. Oznacza to, że w wektorze wyjściowym musimy przewidzieć miejsce na B * 5 wartości. Dlaczego 5? Wynika to z tego, że prostokąt otaczający określany jest 4 wartościami: dwie współrzędne środka obiektu (relatywnie do współrzędnych analizowanej komórki) oraz szerokość i wysokość prostokąta (zapisane jako ułamek wielkości obrazka). Dodatkowo dochodzi 5 wartość, która określa logicznie czy w danej komórce jest obiekt czy go nie ma.
Na samym końcu do wektora wyjściowego należy dołączyć prawdopodobieństwa dla klas – dla każdego z obiektów z osobna. Dla przykładu jeżeli zamierzamy przewidzieć C = 10 klas dla maksymalnie B = 2 obiektów w jednej komórce grida, to ostateczny tensor wyjściowy będzie miał rozmiar: S x S x (B * (5 + C)), równy dla naszego przykładu 4 x 4 x (2 * (5 + 10)) = 4 x 4 x 30.
Zatem uczymy sieć i prowadzimy predykcję zakładając na wyjściu tensor – stąd łatwo zrozumieć dlaczego problem identyfikacji i klasyfikacji obiektu został sprowadzony przez YOLO do problemu klasy regresji.
Dwie istotne kwestie, które być może zwróciły Waszą uwagę:
- W naturalny sposób pojawia się pytanie, czy jeżeli w jakiejś komórce grida algorytm zidentyfikuje obiekt, to czy otaczający go prostokąt jest w jakiś sposób związany z komórką grida? I tak, i nie. Tak, bo w tejże komórce przypada środek prostokąta otaczającego. Nie, bo oczywiście faktyczny prostokąt otaczający prawie nigdy nie pokryje się granicami komórki grida.
- W związku z nakładaniem grida, który ma tyle samo wierszy co kolumn, analizowane obrazki muszą być kwadratowe i mieć zakładany przez daną implementację rozmiar. Jeżeli obrazki są prostokątne i nie odpowiadają oczekiwanym przez sieć rozmiarom, to wiele implementacji algorytmu YOLO dokonuje zmiany rozmiarów obrazków wejściowych i przekształcenia na aspect ratio = 1 (np. uzupełniając obraz czarnym paddingiem).
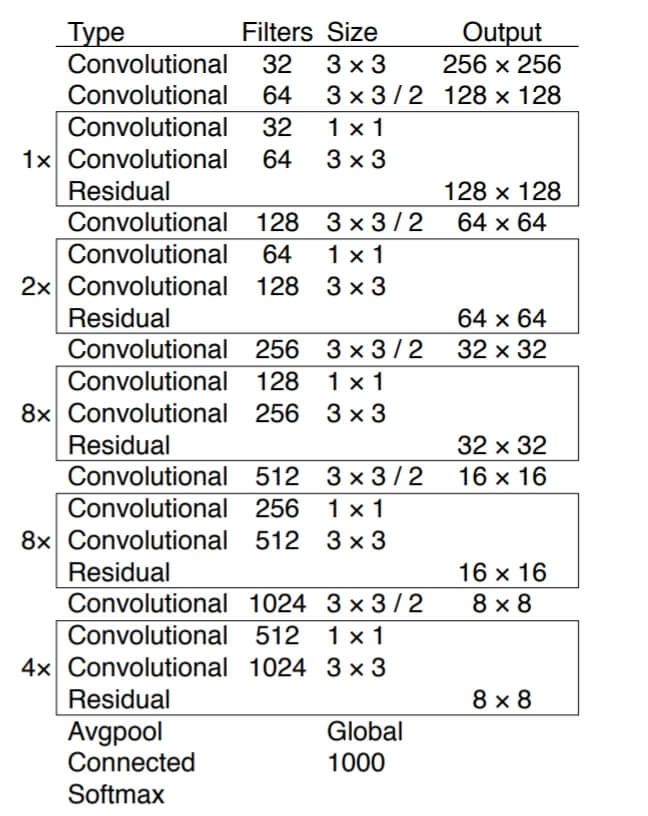
YOLO – struktura sieci
W wersji trzeciej algorytmu autorzy użyli rozbudowanej sieci konwolucyjnej o architekturze zaprezentowanej poniżej. BTW: jeżeli chcecie poznać sieci konwolucyjne od podstaw, to na moim blogu dostępny jest czteroczęściowy tutorial.
Sieć ma aż 53 warstwy konwolucyjne, stąd została nazwana Darknet-53.
YOLO w praktyce
Zobaczmy jak YOLO zachowuje się w praktyce. Instrukcja instalacji jest dostępna na stronie autora, przy czym nie udało mi się jej pomyślnie wykonać na Windows 10. Zalecam zatem od razu przesiadkę na Linuxa lub Maca. Poniższe wskazówki są dla Ubuntu w wersji 20.04.
Do zbudowania klasyfikatora niezbędna będzie możliwość kompilacji z wykorzystaniem gcc. Jeżeli kompilator nie jest zainstalowany w systemie operacyjnym (gcc – -version), to sugeruję wykonanie tych trzech komend:
$ sudo apt update$ sudo apt install build-essential$ gcc --version
Jeżeli wersja kompilatora wyświetla się poprawnie, to możemy przejść do pobrania i skompilowania Darknetu:
$ git clone https://github.com/pjreddie/darknet$ cd darknet$ make
W repozytorium znajduje się kod, nie ma natomiast danych wag wyuczonej sieci. Te musimy ściągnąć oddzielnie. Poniższą komendę należy wykonać z katalogu darknet i tam też powinien być zapisany plik z wagami sieci.
$ wget https://pjreddie.com/media/files/yolov3.weights
W zależności od tego jak dużą ilością pamięci RAM dysponujemy (moje Ubuntu miało tylko 512MB RAM), to należałoby zwiększyć swapfile. Ja zwiększyłem go do 2GB, ale być może mniejsze wartości również wystarczą:
$ sudo fallocate -l 2G /swapfile$ sudo chmod 600 /swapfile$ sudo mkswap /swapfile$ sudo swapon /swapfile
W tej chwili powinniśmy być w stanie uruchomić predykcję dla jednego z przykładowych zdjęć w katalogu data. Poniżej przykład dla pliku kite.jpg. Uwaga: może okazać się konieczne uruchamianie predykcji jako super user – stąd dodane sudo:
$ sudo ./darknet detect cfg/yolov3.cfg yolov3.weights data/kite.jpg
Wynik zapisywany jest na serwerze w pliku predictions.jpg. Należy go pobrać i wyświetlić. Oto wynik klasyfikacji dla latawców – połączone obrazki wejściowy i wyjściowy:

A poniżej użyte przeze mnie prywatne zdjęcie z końmi na wybiegu:
$ sudo ./darknet detect cfg/yolov3.cfg yolov3.weights data/horses-square.jpg

Jak widać patatajce zostały w większości zlokalizowane i poprawnie zakwalifikowane. Dwa z trzech koni na dalekim tle, obrócone tyłem, nie zostały znalezione, ale trzeba przyznać, że również dla ludzkiego oka nie byłoby to łatwe. Akcentem humorystycznym jest kwalifikacja zbiornika z gazem jako konia, ale też trudno nie zgodzić się, że zbiornik w tym ujęciu z daleka przypomina nieco zad konia. 😉
Ta pomyłka ze zbiornikiem jest paradoksalnie potwierdzeniem jednej z silnych cech YOLO – algorytm patrzy na obrazek jako na całość i wnioskuje kontekstowo z całej zawartości obrazu, a nie z wąskiego fragmentu. YOLO ma pewne problemy z detekcją małych obiektów i poradzi sobie gorzej ze scenami przedstawiającymi wiele nakładających się na siebie obiektów, ale generalnie jest to genialna architektura, do tego napisana w C z wykorzystaniem CUDA, co czyni go bardzo szybkim i skutecznym narzędziem detekcji i klasyfikacji obiektów w czasie rzeczywistym.