

Kiedy w 2019 roku zacząłem tworzyć wpisy na tym blogu, pozwoliłem sobie na małą prowokację pisząc „AI zmieni świat bardziej niż rewolucja przemysłowa„. Oczywiście przywidywanie jest bardzo trudne, szczególnie jeżeli dotyczy przyszłości (Niels Bohr), ale ostatnie osiągnięcia w obszarze uczenia maszynowego zachęciły mnie do przemyśleń na temat tego, jak AI zmieni świat w najbliższych 10 latach. A zmieni dość mocno i to jest w zasadzie pewne. W końcu 10 lat to szmat czasu, szczególnie jeżeli technologia wkracza na wykładniczą ścieżkę wzrostu.
Warto w tym miejscu zauważyć, że na takie przemyślenia czeka potencjalna pułapka – łatwo być w przewidywaniach zbyt optymistycznym. Wystarczy sięgnąć do filmów lub tekstów przewidujących 30 lat temu jak będzie wyglądał świat w 2020. Pełno było w nich przewidywań o robotach, latających pojazdach i kolonizacji Księżyca. Nic z tego się nie spełniło. Warto więc podejść do poniższych przewidywań z przymrużeniem oka i z pewnym dystansem.
Zanim przejdziemy do wróżenia, spójrzmy najpierw na kilka ważnych wydarzeń AI w tym kończącym się 2022 roku. Uczenie maszynowe jest już tak szeroką i tak dynamicznie rozwijającą się dziedziną, że w zasadzie brak jest możliwości śledzenia wszystkich wartościowych projektów. Pisząc o ważnych wydarzeniach mam na myśli następujące trzy projekty, które dla mnie w pewnym sensie wyróżniły się z tłumu: Stable Diffusion, GitHub Copilot i udostępniony w ostatnich dniach listopada 2022 ChatGPT. Ten post nie jest o żadnym z tych rozwiązań. Jednak w kilku zdaniach zasygnalizuję, co każdy z tych projektów oferuje. Jeżeli nie widzieliście ich jeszcze w akcji, to warto się tym bliżej zainteresować – przyszłość puka do drzwi.
Stable Diffusion umożliwia generowanie wysokiej jakości obrazów na podstawie tekstu wprowadzonego przez człowieka. Został zbudowany przez kilka organizacji z wiodącą rolą CompVis – Computer Vision & Learning research group na Uniwersytecie Ludwika i Maksymiliana w Monachium oraz firmy Stability AI. Poniżej próbka możliwości rozwiązania ze strony https://stability.ai/blog/stable-diffusion-v2-release. Już wcześniej pojawiały się modele typu text-to-image, takie jak chociażby DALL-E, ale dopiero Stable Diffusion zaoferował kod i parametry modelu w formule open source. Ten i podobne modele mają szansę na zrewolucjonizowanie pracy kreatywnej. BTW: już powstały modele, które generują video.

GitHub Copilot jest narzędziem AI, z którego mogą skorzystać programiści. W dużym skrócie: zaczynacie pisać kod lub wskazujecie co chcecie stworzyć i Copilot podpowiada wam propozycję dalszej części kodu. Na chwilę obecną jest to taki bardziej interaktywny, bardziej inteligentny i łatwiejszy do wykorzystania Stack Overflow. Do narzędzia trzeba się przyzwyczaić, ale wydaje się, że tkwi w nim duży potencjał do podniesienia efektywności. Z narzędziem wiążą się oczywiście kontrowersje związane z prawami autorskimi, pytaniem na ile generowany kod powinno się sprawdzać i nadzorować, niektórzy nie czują się komfortowo prowadząc ciągłą inspekcję nieswojego kodu. Są też oczywiście obawy o to czy takie narzędzia nie zniszczą rynku pracownika w IT. Jestem „z branży”, więc w tym miejscu temat zaczyna się robić nieco delikatny ;-). Idźmy zatem dalej.
ChatGPT jest tak świeżutki, że w dniu pisania tego posta nawet nie ma strony na Wikipedii. Warto tu nadmienić, że jest to model oparty o GPT-3.5, ale z interfejsem zoptymalizowanym w kierunku konwersacji. Jak twierdzą autorzy „The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests”. ChatGPT stał się dość szybko viralem, szczególnie na Twitterze. Przy okazji mała uwaga dla produktowców: silna obecność tematu w mediach daje sporo do myślenia w zakresie tego, jak odpowiednie opakowanie może zmienić percepcję, użycie i ocenę istniejącego produktu (bo GPT-3.5 został już udostępniony w Q1 2022). Funkcjonalnie, oczywiście w dużym skrócie, jest to model konwersacyjny, czyli można z nim porozmawiać na najróżniejsze tematy, można prosić o napisanie krótkiego eseju, wejść w rozmowę na trudne egzystencjalne kwestie. Na Twitterze jest mnóstwo ciekawych przykładów rezultatów zwracanych przez model. Niektóre z nich są mocno zabawne, niektóre dają mocno do myślenia. Duża część z nich, w tym moje poniżej, to nie rozmowa, a bardziej prośba o wygenerowania tekstu spełniającego konkretne, czasami dziwne wymagania.
Chat można sobie samemu wypróbować rejestrując się na stronie https://openai.com/blog/chatgpt/. Z modelem można bawić się na miliony sposobów. Ja dla przykładu poprosiłem go o napisanie krótkiej historii o gekonie, który wykorzystując prywatną znajomość z Elonem Muskiem wybrał się na Marsa.
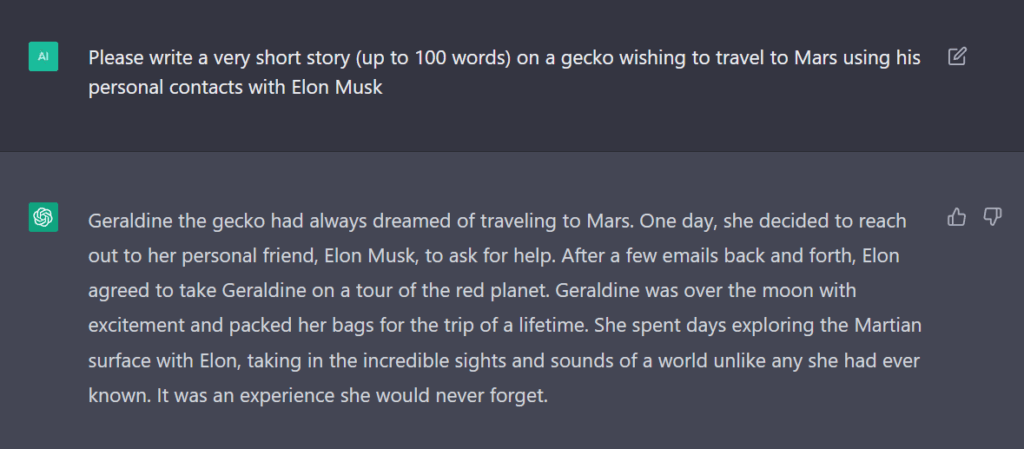
Chcesz napisać przykładowa pracę pisemną na maturę z angielskiego? Proszę bardzo. Wziąłem z netu przykładowy temat (uwaga: link prowadzi do PDFa: https://www.ceziu.pl/images/dokumenty_pdf/matura_angielski/Matura-j.angielski-przykadowe-prace-pisemne.pdf):
Wróciłeś właśnie z ferii Wielkiej Brytanii. Po powrocie zorientowałeś się, że zabrałeś przez pomyłkę, jakaś rzecz należącą do koleżanki z Danii, z którą wynajmowałeś pokój.
Napisz list, w którym:
• Wyjaśnisz na czym polega pomyłka i poinformujesz, jak do niej doszło.
• Opiszesz pomyłkowo zabraną rzecz, podając przynajmniej jej dwie cechy.
• Poprosisz o sprawdzenie, czy kolega / koleżanka nie zabrał/a podobnej rzeczy należącej do ciebie i podaj element, który je różni
• Obiecasz odesłane pomyłkowo zabranej rzeczy i poprosisz o to samo.
Pamiętaj o zachowaniu odpowiedniej formy i stylu listu. Nie umieszczaj żadnych adresów. Podpisz się jako XYZ. Długość listu powinna wynosić od 120 do 150 słów.
Przetłumaczyłem w Google Translate do poniższej postaci …
Just got back from UK holidays. After returning, you realized that you took, by mistake, some thing belonging to a friend from Denmark, with whom you rented a room.
Write a letter in which:
• Explain what the mistake is and how it happened.
• You will describe the mistakenly taken item, giving at least two of its characteristics.
• You will ask to check whether a colleague has taken a similar item belonging to you and specify the element that makes them different
• Promise to return the wrongly taken item and ask for the same.
Remember to keep the proper form and style of the letter. Do not include any addresses. Sign as XYZ. The length of the letter should be between 120 and 150 words.
i poprosiłem ChatGPT o napisanie listu zgodnie z tymi wytycznymi. Oto wynik:
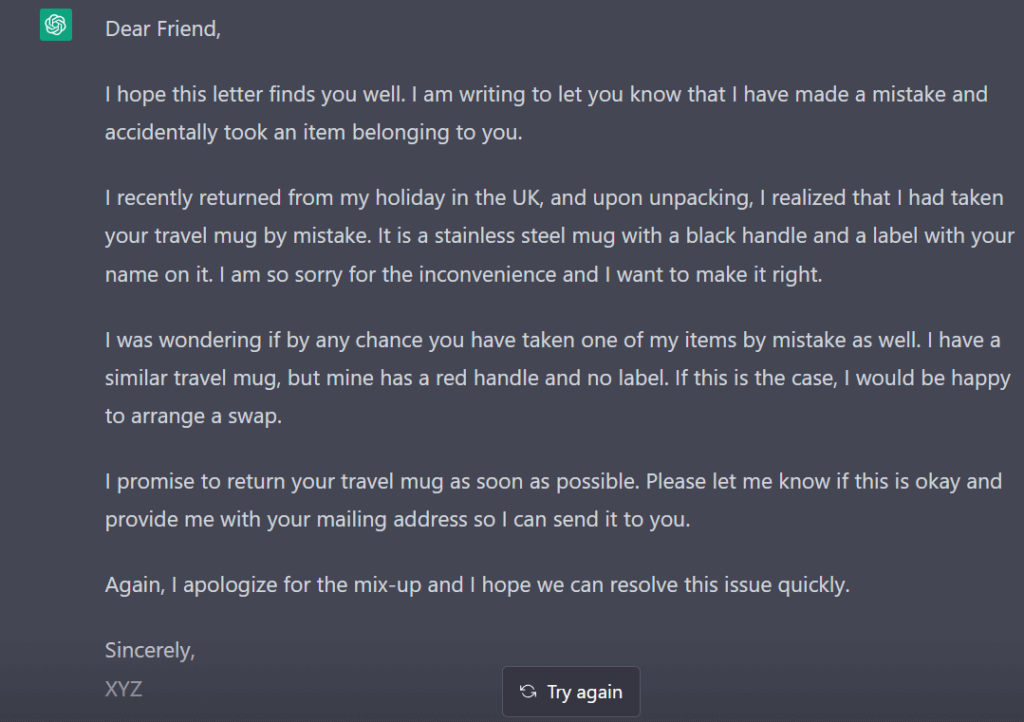
Zacząłem się przez chwilę zastanawiać z synem, ile można w jego liceum wziąć od uczniów za napisanie jednego zadania domowego z angielskiego, ale doszliśmy szybko do wniosku, że wieści rozejdą się błyskawicznie i biznes upadnie. Plus nie do pominięcia jest fakt, że mogłoby to być źle odebrane przez szkołę. 😉
Wiemy co leży na stole dziś, wybierzmy się zatem w podróż w czasie…
Przez głupie eksperymenty z czasoprzestrzenią, jakie w weekendowe wieczory prowadzisz w garażu, obudziłeś się niespodziewanie w roku 2032. Nerwowo wpisujesz na telefonie google.com, aby sprawdzić co się dzieje na świecie. Jak to „Ta witryna jest nieosiągalna„? Czyżby Google wypadł z gry?
Nieeee, no żartuję. Z Google wszystko będzie ok, bo od wielu lat mają świetne zespoły AI i na pewno pracują nad nowym modelem wyszukiwania informacji. Takim, który będzie można przede wszystkim bardzo skutecznie monetyzować – jak obecny model. Teoretycznie jednak, jeżeli Google z tym niewiele zrobi, to jeżeli ktoś w 2032 roku będzie chciał się dowiedzieć kto i dlaczego został prezydentem Stanów Zjednoczonych w 2028, to w zasadzie będzie mógłby spytać o to ChatGPT w jego wersji 7, czy jaka tam wersja będzie wtedy obowiązująca. Będzie mógł o to spytać, podobnie jak my możemy już spytać obecną wersję ChatGPT o wybory w 2016 roku.
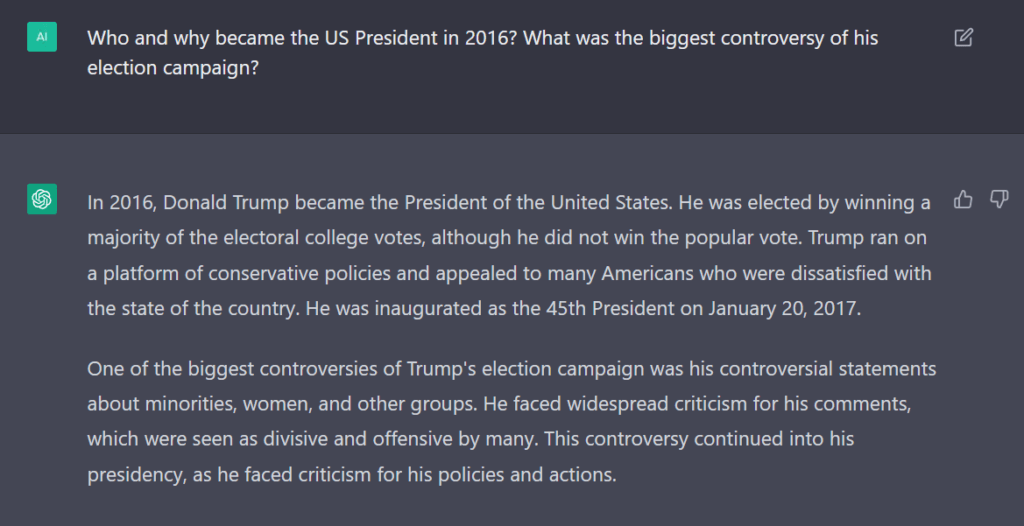
A całkiem serio, sposób w jaki będziemy prowadzić wyszukiwanie informacji będzie w 2032 roku całkowicie inny i oparty w większości o sztuczną inteligencję z interfejsem konwersacyjnym.
Istotnej zmianie ulegnie również sposób, w jaki rozwiązujemy skomplikowane problemy w praktycznie wszystkich dziedzinach nauki. Obecnie powszechnie przyjętym schematem jest stworzenie zespołu wysokiej klasy specjalistów w danej dziedzinie, którzy budują lub wykorzystują teoretyczne podstawy danej nauki, aby w praktyce stworzyć nowy artefakt świata fizycznego: nowy lek, nową substancję chemiczną, czy nowe urządzenie. Na początku następnej dekady powinniśmy obserwować przesunięcie tego schematu w kierunku najpierw zbudowania modelu AI, który będzie w stanie zaproponować teoretyczne lub praktyczne rozwiązanie danego problemu, a dopiero potem przejęcie, sprawdzenie i wdrożenie w praktyce pomysłu przez zespół specjalistów.
Powszechne stanie się korzystanie z doradców AI. Już obecnie nasz ChatGPT jest w stanie podjąć próbę rozwiązania niektórych problemów różnej natury. Stable Diffusion może nas natchnąć ciekawym pomysłem na oprawę graficzną. A GitHub Copilot podpowiedzieć kod. Rozwiązując poniższy problem ChatGPT popełnił dość oczywisty i prosty błąd. Ale jest to model językowo-konwersacyjny, a nie model matematyczny. To co robi największe wrażenie już obecnie, to właściwy – iteracyjny sposób podejścia modelu do rozwiązania problemu.

W najbliższych latach powstaną wyspecjalizowane modele będące w stanie wspomagać inżynierów w rozwiązywaniu trudnych zagadnień. Te modele, które będą nieco prostsze i tańsze lub darmowe (np. matematyczne, językowe, historyczne) ograniczą sens zadawania nastolatkom szkolnych zadań domowych. Skoro nastolatek będzie w stanie na komórce rozwiązać zestaw równań lub wygenerować pracę językową, nie będzie sensu kontynuowania wątpliwej według mnie praktyki zlecania zadań domowych. Wymusi to w końcu zmianę sposobu nauczania dzieci i młodzieży. Nastąpi odejście od modelu opartego na zapamiętywaniu setek, często bezużytecznych w danej chwili dla dziecka informacji, w kierunku modelu, który promuje umiejętność znalezienia informacji i rozwiązania z ich pomocą danego problemu. Oczywiście już i teraz są kraje, które doskonale zreformowały szkolnictwo. Piszę zatem o tym głównie z perspektywy ojca mającego syna w polskiej szkole.
Rewolucja modeli specjalistycznych (tzw. Narrow AI) będzie dotyczyła również innych branż, często mniej technicznych niż IT, fizyka, chemia czy biologia. Mogę wyobrazić sobie robota AI analizującego w 2032 stan prawny w danym obszarze i doradzającego profesjonalnemu prawnikowi w kwestii podejścia do danej sprawy karnej. W krajach gdzie dostęp do służby zdrowia jest mocno ograniczony, powszechne stanie się korzystanie z serwisów medycznych. Dla mieszkańców zachodniego świata być może wydaje się to obecnie nie do przyjęcia, ale mieszkańcy wielu regionów naszej planety po prostu mogą nie mieć fizycznej możliwości bezpośredniego skonsultowania się z dermatologiem lub psychologiem lub po prostu nie stać ich na to. Obecnie podobne odejście od usług tradycyjnych do usług następnej generacji obserwujemy w krajach, w których z różnych przyczyn mamy do czynienia z uciskiem finansowym. Hiperinflacja, opresyjne rządy, brak prostego dostępu do usług bankowych powodują, że ludzie naturalnie sięgają do płatności Bitcoinem. Życie nie znosi próżni, więc jeżeli nie będzie dostępu do lekarza, a będzie dostęp do internetu, to sami wiecie co się stanie.

Rewolucja AI nie ominie oczywiście samej branży IT. Czy piłujemy gałąź, na której obecnie wygodnie siedzimy? Ogólny schemat tego, w jaki sposób tworzymy oprogramowanie niewiele zmienił się w ostatnich 20 latach. Nadal należy ustalić ze sponsorem / klientem wymagania biznesowe, przełożyć je na wymagania techniczne, zaprojektować architekturę i zacząć pisać kod. Kod jest w IT źródłem prawdy. Prawdy o tym jak działa system i prawdy o tym jak dobry jest programista. Umiesz dobrze kodować? Będziesz dobrze żył! Oczywiście zmieniły się języki programowania, powstały tysiące zaawansowanych narzędzi, agile na całe szczęście zdominował styl pracy, ale ogólna metodologia pozostała niezmieniona. Dodatkowo, AD 2022 mamy rynek pracownika, zapotrzebowanie na usługi IT pozostaje niezmiennie wysokie i prawie wszyscy są zadowoleni. Co może pójść nie tak? 😉
Obecnie rozwiązania typu Copilot będą pełniły rolę lokalnego Stack Overflow. Jednak czy nam się to podoba czy nie, w przeciągu kilku lat różnej maści copiloty staną się coraz bardziej zaawansowane. W mojej opinii kodowanie będzie stopniowo ewoluowało od pisania kodu poprzez wystukiwanie każdego znaku na klawiaturze, przerywanego okresowym copy-paste ze Stack Overflow, do opisywania oczekiwanego rezultatu i analizy zaproponowanego przez copilota rozwiązania. Nadal konieczna będzie bardzo dobra znajomość składni, nadal niezbędne będzie rozumienie i ręczne programowanie przepływu informacji na wyższym poziomie, ale efektywność tworzenia prostych funkcjonalności czy to biznesowo-backendowych czy frontendowych będzie dużo wyższa. Dużo bardziej zaawansowana będzie analiza poprawności zapisanego kodu i usuwania błędów. Pamiętajmy, że w 2032 roku tego typu konwersacja jak poniżej, będzie dużo bardziej skuteczna, szybsza i precyzyjna.
„Jest 2022, jestem programistą, co ja mam teraz zrobić? Jak mam utrzymać rodzinę?” Myślę, że obawy co do tego, że AI zabierze nam – informatykom – część pracy są nieco przesadzone lub przedwczesne. Niemniej, jako programista zamierzam z ciekawością obserwować te narzędzia i próbować włączać je do swojego arsenału umiejętności. A jako menadżer zamierzam z ciekawością obserwować te narzędzia i zachęcać programistów do stopniowego włączania ich do arsenału ich umiejętności. 😉
Wracamy do rzeczywistości AD 2032. A tam bardzo duże państwo (oznaczmy je literą C), które ma chrapkę na pewną niewielką wyspę, ale boi się dominacji militarnej innego bardzo dużego państwa (oznaczmy je literą A), jest w trakcie wprowadzania znacznej reformy w swojej armii i uzbrojeniu. Reforma ta została zainicjowana po bardzo szczegółowej analizie, jaką C robiło w trakcie napaści Rosji na Ukrainie w 2022. Wojna ta zakończyła się ostatecznie totalną porażką Rosji i upadkiem reżimu, ale zwróciła uwagę wszystkich na wyjątkową skuteczność działania małych pół-autonomicznych jednostek bojowych, które wówczas nazwane były dronami oraz oczywiście na ogólne znaczenie przewagi technologicznej (to akurat znane było od stuleci). Państwo C, czy nam się to na Zachodzie podoba czy nie, spędziło całą dekadę lat 20 na budowaniu coraz większych kompetencji w militarnym wykorzystaniu AI, dzięki czemu uważa się obecnie (w 2032), że C jest w stanie militarnie przyłączyć małą wyspę do swojego terytorium i to mimo wsparcia tej wyspy przez A i przez inne kraje zachodnie.
Wyżej opisana sytuacja zaskoczyła nieco zachodni establishment. Wprawdzie Państwo A ma również bardzo zaawansowane rozwiązania militarne, nawet bardziej zaawansowane niż C, ale ze względu na odległość dzielącą małą wyspę od A, pomoc może być ograniczona. Europa w zasadzie przestała się liczyć w tej kwestii. Protesty społeczne, jakie pojawiły się w Europie pod koniec lat 20 w związku z obawami o zabieranie miejsc pracy przez AI, oraz w związku z ogromnym zapotrzebowaniem AI na energię niezbędną do trenowania coraz większych modeli, zwróciły uwagę europejskich populistycznych polityków, którzy chcąc zyskać na popularności i powołując się na dobro społeczne oraz ekologię uzyskali poparcie dużej części europejskich wyborców i zaczęli hamować rozwój AI w Europie. Czytaliście może Diunę? Dla mnie jedna z trzech najlepszych powieści science-fiction. Genialny Herbert w roku 1963 (sic!) opisał w niej profesję Mentata jako ludzkiego odpowiednika komputerów. Ludzi trenowano na mentatów, gdyż po wojnie ludzi z maszynami prawo zabraniało tworzenia maszyn na podobieństwo ludzkiego umysłu. Mam nadzieję, że Frank był po prostu genialny a nie, że był prorokiem losów Europy.
Ogromnym zagadnieniem przez całą dekadę lat 20 będą kradzież tożsamości, wszelkiego rodzaju fake newsy i związane z tym inklinacje do cenzurowania. Temat cenzury i wolności słowa nieco odbiega od tematu posta. Nadmienię więc jedynie, że z perspektywy post-covidowej w mojej opinii duże domy medialne nie zdały egzaminu i nie są już dla społeczeństw żadną gwarancją, że prezentowane nam papki informacyjne są zbliżone do prawdy i dają pole do dyskusji. W dużej części przypadków okazało się, że prezentowane treści są albo niesprawdzone, albo umotywowane politycznie lub ekonomicznie (ukierunkowane na sensację i klikalność). Największe nadzieje w zakresie wolności słowa wiążę z Twitterem, który pod rządami Muska ma szanse stać się najlepszym źródłem informacji, bo informacji płynącej bezpośrednio od zróżnicowanej poglądowo grupy ludzi zainteresowanych daną dziedziną. Jeżeli treści na Twitterze nie będą tendencyjnie filtrowane, to będzie to dużo lepsza platforma informacyjna niż serwowana nam papka przefiltrowana przez pana redaktora naczelnego nawet najlepszego outletu medialnego.
W mojej opinii wraz ze wzrostem możliwości AI walka z kradzieżą tożsamości i fake news będzie coraz trudniejsza. Mogę wyobrazić sobie, że realizowana obecnie telefonicznie „metoda na wnuczka” może być niewielkim kosztem efektywniej zrealizowana na warstwie wizualno-głosowej, gdzie AI w czasie rzeczywistym zmoduluje wygląd i brzmienie głosu, próbując wyłudzić od atakowanego cenne informacje lub zmusić go do przekazania środków pieniężnych. Ja swojemu synowi już przekazałem, że nawet jakby wyświetlił mu się mój numer, nawet jakby usłyszał w telefonie mój głos i nawet jak na facetime zobaczy moją twarz, a ten niby-ja będzie się zarzekał, że potrzebuje kasy, bo znalazł się w trudnej sytuacji o 3 ranem, to żeby pod żadnym pozorem syn nie oddawał ostatnich zaskórniaków ze swojego kieszonkowego żadnemu „mojemu koledze”, który za chwilę podjedzie po dom, aby odebrać kasę. Pewnym rozwiązaniem problemów z kradzieżą tożsamości i fake-newsami jawi się zastosowanie w większym stopniu kryptografii i technologii publicznego blockchain, ale to temat dla innych specjalistów.
Duże zmiany czekają twórców na polu kreatywności. Codziennością stanie się korzystanie z modeli generacyjnych, które będą generowały obrazy, video i muzykę. Osobiście nie uważam, aby modele generacyjne były dużym zagrożeniem dla artystów i twórców. Będą raczej wspierały ich naturalne predyspozycje i staną się dodatkowym istotnym narzędziem. Mogą jednak doprowadzić do mniejszego zapotrzebowania na pracę ludzką w obszarach, które nie wymagają utworów wysokiej jakości. Szata graficzna dla prostych stron internetowych, obrazki na blog zamiast zdjęć wykonywanych przez fotografów, elementy graficzne w grach z niskiej i średniej półki. Nie widzę przeszkód, aby wszystkie one były generowane przez modele AI, pod nadzorem grafika. Stawiałbym również na to, że AI zwiększy dostępność dla osób kreatywnych, które nie posiadają obecnie wystarczających zdolności manualnych lub technicznych. Coś jak rap, który otworzył muzykę dla osób, które niekoniecznie umieją dobrze śpiewać, potrafią jednak tworzyć ciekawe sample i pisać dobre teksty. W sztuce pojawi się nowa kategoria – sztuki wygenerowanej. A dzieła wykonywane tradycyjnie / ręcznie będą postrzegane jako zdecydowanie bardziej wartościowe.

Rozwiązania AI zbliżą się w następnej dekadzie do Świętego Graala sztucznej inteligencji, czyli do General Artificial Intelligence (AGI). Obecnie większość rozwiązań operuje w dość wąskiej dziedzinie: modele językowe, rozpoznawanie obrazów, modele generacyjne, modele eksperckie – tak zwane Narrow AI. Kolejnym naturalnym krokiem jest obranie strategii bottom-up, czyli próba stworzenia rozwiązania, które będzie łączyło funkcjonalność wielu wąskich modeli i tym samym będzie w stanie realizować o wiele bardzie złożone i wielodziedzinowe zadania. Czy to jednak pozwoli je nazwać mianem AGI?
Branża nadal mierzy się ze ścisłym zdefiniowaniem pojęcia AGI. Istnieje co najmniej kilka propozycji testów (Turing Test, Coffee Test, Robot College Student Test, Employment Test), ale konsensusu w tej materii brak. Wraz z powstawaniem coraz bardziej zaawansowanych rozwiązań, prawdopodobnie pojawią się bardziej formalne definicje i korporacje rozpoczną ostatnią fazę wyścigu o miano pierwszej organizacji, która wytworzyła AGI. Zastanawiam się jedynie, czy do wytworzenia AGI wystarczy nam królestwo cyfrowe? Czy trening nie będzie musiał wyjść poza kompresję internetu i przejść do świata fizycznego? Być może modele, które będą stanie czuć zapachy i rozpoznawać smaki oraz dotyk, w naturalny sposób zyskają nowe umiejętności, niejako „wyjdą do ludzi”, i tym samym rozszerzą swoją sztuczną świadomość. Być może w latach trzydziestych doczekamy się pierwszej restauracji z posiłkami robionymi wedle przepisów AI? Czy otrzyma ona Gwiazdkę Michelin?
Po co to wszystko, czyli czas na podsumowanie
Tempo zmian na świecie oraz złożoność procesów i to praktycznie w każdej dziedzinie jest tak wysokie, że przewidywanie tego co się zdarzy za 3 kwartały jest bardzo trudne. Wystarczy spojrzeć na ekonomię – naukę z blisko 250-letnią historią, licząc od Adama Smitha – z jej aktualnymi (grudzień 2022) wątpliwościami co do tego, co nas czeka w globalnej gospodarce w 2023. A co dopiero przewidywanie zmian na przestrzeni dekady i to w tak innowacyjnej dziedzinie jak uczenie maszynowe. Być może powyższe przewidywania okażą się niepotrzebne i nietrafione, a ja zostanę za chwilę bezlitośnie wypunktowany przez kolegów i czytelników, kto wie? Myślę jednak, że od czasu do czasu warto oderwać się od ziemi, wznieść się myślami w chmury i puścić wodze fantazji.
Ostatnie osiągnięcia w dziedzinie sztucznej inteligencji, których kilka wyróżniających się przykładów podałem powyżej (Stable Diffusion, GitHub Copilot, ChatGPT), utwierdzają mnie w przekonaniu, że rewolucja AI rozpoczęła się na dobre. Wątpliwości co do tego, czy czeka nas kolejna zima AI, można w zasadzie uznać za na jakiś czas rozwiane. Oczywiście branża nadal stoi przed wieloma wyzwaniami. Jednym z najbardziej fundamentalnych jest jak monetyzować AI? Jak wykorzystać modele budowane przez inżynierów w realnej gospodarce? To nie jest ani oczywiste, ani proste, może też spotykać się ze znacznym oporem społecznym. A przecież nadzieje związane z AI w kontekście gospodarczym są olbrzymie. Trzy dekady, licząc od lat 90-tych, były dezinflacyjne głównie dzięki trzem siłom: postępowi technologicznemu, dostępności taniej energii i globalizacji wynikającej z otwierających się gospodarek Chin i Europy Środkowo-Wschodniej. Zalały one świat tanią siłą roboczą i równolegle stworzyły silne rozwijające się rynki zbytu dla produktów i usług starych ekonomii. Na początku lat 20-tych, wraz nasyceniem się tych rynków, wraz covidem i wojną w Ukrainie, wydaje się, że co najmniej 2 z tych sił zostały na jakiś czas lub bezpowrotnie utracone. Czy AI przejmie pałeczkę?
Jeszcze innym zagadnieniem przed jakim stoi świat AI, jest sposób w jaki cały czas trenujemy modele, wykorzystując do tego różne wariacje metody gradientu prostego. Być może to stanie się wkrótce główną przeszkodą na drodze do AGI i dopóki nie zostanie znaleziona metoda lepsza, AI będzie tkwiła w pewnym zawieszeniu.
Podane powyżej przewidywania proszę oczywiście potraktować z dużym przymrużeniem oka. Były one dla mnie okazją do ćwiczenia intelektualnego. Stały się też łatwym pretekstem do chwilowego „wyjścia z pudełka” i oderwania się od codziennej pracy i nauki. Proszę z góry o wybaczenie szczególnie tych, u których powyższe przewidywania wytworzyły jakiś poziom dyskomfortu lub niepokoju. ;-). Na koniec przyznam, że po cichu liczę, że te mniej pozytywne przewidywania się nie spełnią, a te bardziej optymistyczne zaskoczą nas skalą manifestacji, czego wszystkim czytelnikom życzę.