

Until recently, a large part of the key concepts in the field of artificial intelligence was not so clearly defined. Some of them, such as Deep Learning, were even referred to as “buzzwords”, term used mainly by marketing and not strictly translated into scientific areas. Now, the basic concepts seem to have taken hold, and most AI professionals agree on what they mean. As certain definitions appear throughout most of my blog posts, as well as in articles, tutorials and courses available on the web, I decided to bring them to you as clearly as possible.
After reading this post:
- You will organize your knowledge of four key concepts of AI: artificial intelligence, machine learning, neural networks and deep learning.
- You will learn what are the differences between supervised and unsupervised learning.
- You will be able to tell what the training, testing and validation datasets are and what is the overfitting.
- You will be able to define what are hyperparameters and model parameters.
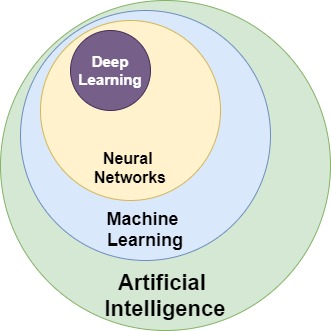
Artificial intelligence vs machine learning vs deep learning
The most questionable is the distinction between the concepts of artificial intelligence, machine learning, deep learning, their relationships, and how extremely popular neural networks fit into it all.
Artificial intelligence is the broadest concept that defines a de facto new field of science. Similar to mathematics, physics or chemistry. This concept has a more theoretical and philosophical meaning than a practical one and has existed since the mid-1950s, when the first unsuccessful attempts at mathematical modeling of the functioning of the human brain were made. I will give you my favorite, simple definition:
AI is the science of how to build a machine that will be able to perform tasks in a way that can be called intelligent
Currently operating artificial intelligence systems cover narrow domains and are often referred to as “narrow” or “applied”. For example, artificial intelligence is able to win GO or chess against a grandmaster. It can handle speech and writing very well. It will enable quick and effective recognition of the surrounding environment, e.g. objects on and around the road. However, the holy grail of AI is the so-called “general AI”, which is to enable the machine to effectively solve a large group of various problems, i.e. to behave largely like a human. So far, no one has even managed to get close to this goal. Some predict that the first general AI models will emerge as a combination of multiple “narrow” models, which seems to be the only reasonable and feasible route at the moment. Although who knows what is happening in the privacy of the strictly protected rooms of Chinese and American corporations. Fortunately, the road to the real Skynet is very far, if at all achievable.
Machine learning is only a part of the broader scientific domain of artificial intelligence. The most distinctive feature of machine learning is the ability to automatically learn and improve through the acquisition of new knowledge to solve a problem, but without implementing a dedicated algorithm.
I find this last part of the sentence particularly important in distinguishing machine learning from other “intelligent” software. You can write a very effective, dedicated algorithm that will predict the occurrence of precipitation based on the current look of the sky, but it will not be machine learning. Machine learning will be collecting a large number of photos of the sky, along with information whether there has been precipitation or not, and processing of this data by one of the machine learning algorithms (e.g. logistic regression, KNN, neural network, etc.), in order to obtain a model effectively predicting the occurrence of rainfall.
Neural networks are one of the algorithms / ways of machine learning. This algorithm uses mathematical structures in behavior similar to the actions of human neurons. Such artificial neurons, connected in a network, receive signals at the input and perform a relatively simple operation on them, emit an output signal, which is sent to the next layer of neurons or to the output of the network as a result of its operation. The network entry can be, for example, the values of individual pixels from a photo of the sky or the data of a credit application, appropriately processed into the digital form.
Each input signal to an artificial neuron has a weight that either strengthens or weakens the output of that neuron. During network training, using the feedback, the neural network training algorithm modifies the weights assigned to individual neurons so that the network response is burdened with the lowest possible error. The error is calculated by comparing the network response to the dataset (e.g. sky appearance) with the correct response – this is the so-called supervised learning. Computational methods, including gradient descent algorithms, are used to implement the feedback, i.e. the appropriate correction of neuron weights, thanks to which the network “learns” to better recognize data. All this in the hope that by showing new data to the network, e.g. the current appearance of the sky, not previously seen by the network, we will get a correct forecast.
And finally we come to deep learning – a fascinating branch of machine learning, that uses very complex neural networks, huge – let me emphasize it again – HUGE amounts of data and unattainable, until recently, computing powers, to teach the computer things that seemed only within human mind reach. In recent years, deep learning has proved to be very effective in solving problems related to image recognition, speech, broadly understood interaction with the environment (robots, cars), but also in medicine, game testing and fraud detection.
The relationship between the above-mentioned terms is illustrated in the figure below.
Supervised vs. unsupervised learning
Supervised learning is like a teacher working with a child. A child receives a set of pictures with information about what is in the picture: here is a horse, here is a tree, here is a car – let’s call this stage the training phase. After enough trials, you can ask a child “what’s in the picture?”, showing a slightly different car, a different species of tree, or a horse with a different color. We could call it the testing phase whether a child has learned the concepts correctly and, more importantly, is able to generalize the acquired knowledge. In other words, is it still able to recognize the object as a tree by seeing the tree, but not the same tree as in the training phase? If it is not, we repeat the training process until it is successful.
For humans, supervised learning is natural, and we are very good at it. In the digital world, supervised learning is based on a training dataset which, on the one hand, shows the input data and, on the other, its description, often called a label or target. The input data is usually laboriously prepared in advance by a human. For example, a human describes each of the tens of thousands of pictures that she/he intends to use in the training process. The algorithm learns to classify or predict values based on the input data of the training set and labels. Training takes place on the basis of sequential trials, error evaluation and feedback so that the algorithm can correct its operation, if necessary. Then, after a machine is trained, we can present the dataset without a target and ask for a class or value prediction.
Unsupervised learning is like working without a teacher. We receive a set of data and our task is to group them or find certain structures and dependencies (sometimes hidden), without first indicating what we are looking for or what classes we should divide the data into. Imagine that we have received a group of photos of various microbes and, without knowing biology, we have to group them, taking into account, for example, similarities and differences in appearance or observable behavior.
The data used for unsupervised learning does not have to be labeled. Therefore, they are much easier to prepare than data for supervised learning. Unfortunately, unsupervised learning can be effectively used in fairly narrow applications. Examples include clustering, which enables the division of a data set into groups of similar data or so-called autoencoders, thanks to which, without knowing about the specificity of the analyzed dataset, we can compress it into a form that will contain more valuable information (noise removing).
Types of datasets and overfitting
While discussing the machine learning types above, I referred to two types of datasets: training and test. In fact, we have one more – the validation dataset. It is worth taking a moment and look closer at those datasets.
The division into such three sets can be well explained by analogy to learning the subject in college. In the first phase, students are presented with material during lectures. Students listen to lecturers, take notes, try to understand the examples given. In other words, they work on the training dataset. I will ignore the fact that the lectures are sometimes optional, 😉 here it is not the best analogy to machine learning, where the training phase simply cannot be skipped.
Then, students go to exercise classes where they solve problems on their own, but still under the supervision of the lecturer. This is work on the validation dataset. It is to show how well the student has absorbed the knowledge from the lecture, whether his/her current skills are sufficient or if the material should be additionally explained. The training process on the test (lecture) and validation (exercises) datasets is repeated many times. In the case of machine learning, it has to be repeated much more often, even tens or hundreds of thousands of times. After all, it is known for a long time that no machine is as effective as the student just before the exam. 😉 At the end of the semester comes such a well-liked moment – the exam. Final confirmation of the skills acquired during the lectures and exercises. Students receive material that they have not seen before and have to independently demonstrate the appropriate skills. This is work on the test dataset.
In the problem that we want to solve using a selected machine learning algorithm, we must have a dataset at our disposal – often very large. In practice, such a dataset is divided into a training dataset and a test dataset, usually in the proportion of 80/20. Such a procedure is necessary to be able to assess, after training the model, whether it has acquired the ability to generalize. In other words, will it also correctly evaluate data that it has not seen in the training process. If we do not separate the test dataset, we will not be able to determine whether the trained model solves the task well, or whether it has simply learned to recognize data from the training dataset and it will not do so well when presenting a completely new data.
By the way: the phenomenon that occurs when the model remembers the training dataset, instead of generalizing it, is called overfitting. The algorithm has over-adjusted to the data and thus cannot handle data outside the training dataset as well.
Often, the validation dataset is separated from the training dataset. The algorithm does not learn on the validation dataset, but only on the training one, and the validation dataset is used to check the effects during training process, in order to properly adjust the model hyperparameters (more on them below). There is generally a lot of confusion with the definition of the validation dataset. Different specialists define it a bit differently. Different libraries implement splitting differently. But the general sense remains the same: the validation dataset is to evaluate the training process as it progresses.
Can we use the validation dataset as a test one to evaluate the effectiveness of the trained model? Unfortunately not. Although the validation dataset is not directly used in the training process, by influencing the model’s hyperparameters, it has a significant impact on the way the model works and thus is not suitable for an objective assessment of its effectiveness.
What are hyperparameters actually?
Since we have already referred to hyperparameters several times, it is worth taking a closer look at them. Before we move on to hyperparameters, however, it is worth determining what the model parameters are, because distinguishing between them is often problematic.
The primary goal of machine learning is to process a dataset in such a way that a certain mathematical model is created that we can then use for prediction. During the construction of the model, we use optimization algorithms so that the model predictions become more and more accurate. These algorithms work largely by tuning a series of variables describing the model. These variables are called model parameters. They are not set manually, but result from the analysis of the training dataset and their automatic optimization by the algorithm.
An example of model parameters are weights assigned to individual neurons in the neural network, and in the case of logistic regression these will be the ω coefficients of the following polynomial that defines an n-dimensional plane that divides data into classes:
y =ω1*x1+ω2*x2+…+ωn*xn
Unlike model parameters, hyperparameters are external to the model and are not derived from the data in the training dataset. They are usually determined by the engineer supervising the construction of the model, and their optimal value is unknown. They are most often initially determined on the basis of best practices and then their values can be adjusted to the training outcomes accordingly.
Examples of hyperparameters include k, i.e. the number of neighbors in the k-nearest neighbors algorithm, the number of neural network layers and the number of neurons in each layer, or the learning rate, which determines how quickly we move through the loss function to find its minimum.
To sum up, the model parameters are set automatically on the basis of the training dataset, and the hyperparameters are set manually based on good practices and the results achieved by the model, and their primary role is to de facto optimize the algorithm so that it determines the best model parameters.
I hope this post has introduced you to the basic concepts of artificial intelligence and machine learning. Good understanding of them will certainly help you in effective further learning.
Do you have any questions? You can ask them in comments.
Did you like my post? I will be grateful for recommending it.
See you soon on my blog, discussing another interesting topic!
Are you an NBA fan? Check my free NBA Games Ranked service and enjoy watching good games only.