

Jeszcze do niedawna duża część kluczowych pojęć z zakresu szeroko rozumianej sztucznej inteligencji nie była jednoznacznie zdefiniowana. Niektóre z nich, jak Deep Learning, były nawet określane mianem “buzzwords”, czyli pojęć używanych głównie przez marketing i nie mających ścisłego przełożenia na obszary naukowe. Obecnie wydaje się, że podstawowe pojęcia ugruntowały się i większość osób zajmujących profesjonalnie AI jest zgodna co do ich znaczenia. Ponieważ pewne definicje przewijają się przez większość postów na moim blogu, a także są obecne w artykułach, tutorialach i kursach dostępnych w sieci, to postanowiłem przybliżyć je wam w możliwie najbardziej przejrzysty sposób.
Po przeczytaniu niniejszego posta:
- Uporządkujesz sobie wiedzę na temat czterech kluczowych pojęć AI: sztuczna inteligencja (artificial intelligence), uczenie maszynowe (machine learning), sieci neuronowe (neural networks) oraz głębokie uczenie (deep learning).
- Dowiesz się jakie są różnice między uczeniem nadzorowanym i nienadzorowanym.
- Będziesz w stanie opowiedzieć czym są zbiory: uczący, testowy i walidacyjny oraz na czym polega zjawisko overfittingu.
- Określisz czym są hiperparametry, a czym parametry modelu.
Sztuczna inteligencja a uczenie maszynowe a głębokie uczenie
Z reguły najwięcej wątpliwości budzi rozróżnienie pojęć sztucznej inteligencji, uczenia maszynowego, uczenia głębokiego, ich wzajemnych relacji oraz jak w to wszystko wpasowują się niezwykle popularne sieci neuronowe.
Sztuczna inteligencja (AI) jest najszerszym pojęciem określającym de facto nową dziedzinę nauki. Podobną do matematyki, fizyki, czy chemii. Pojęcie to ma bardziej teoretyczno-filozoficzny wydźwięk niż praktyczny i egzystuje od połowy lat pięćdziesiątych, kiedy to podejmowano pierwsze nieudane próby matematycznego modelowania funkcjonowania ludzkiego mózgu. Podam Wam moją ulubioną, bo prostą definicję:
AI to nauka o tym jak zbudować maszynę, która będzie w stanie wykonywać zadania w sposób, który można nazwać inteligentnym.
Obecnie działające systemy sztucznej inteligencji dotyczą wąskich dziedzin i są często określane mianem “narrow” lub “applied”. Dla przykładu, sztuczna inteligencja jest w stanie wygrać w GO lub w szachy z arcymistrzem. Bardzo dobrze poradzi sobie z przetwarzaniem mowy i pisma. Umożliwi szybkie i skuteczne rozpoznawanie otoczenia, np. obiektów na i wokół drogi, itp. Świętym graalem AI jest jednak tak zwana “general AI”, która ma umożliwić maszynie skuteczne rozwiązywanie dużej grupy różnorodnych problemów, czyli zachowywać się w dużej mierze jak człowiek. Jak na razie nikomu nie udało się nawet zbliżyć do tego celu. Niektórzy przewidują, że pierwsze modele general AI będą powstawały jako połączenie wielu modeli “narrow”, co wydaje się na chwilę obecną jedyną rozsądną i wykonalną drogą. Choć kto tam wie, co się dzieje w zaciszu ściśle chronionych pokojów chińskich i amerykańskich korporacji. Droga do prawdziwego Skynetu jest na szczęście bardzo odległa, jeśli w ogóle osiągalna.
Uczenie maszynowe jest jedynie częścią szerszej domeny naukowej, jaką jest sztuczna inteligencja. Najbardziej charakterystyczną cechą uczenia maszynowego jest umiejętność automatycznego uczenia się i doskonalenia poprzez nabywanie nowej wiedzy, w celu rozwiązywania problemu, ale bez implementacji dedykowanego algorytmu.
Ten ostatni fragment jest wg mnie szczególnie istotny dla rozróżnienia uczenia maszynowego od innego “inteligentnego” oprogramowania. Można napisać bardzo skuteczny, dedykowany algorytm, który będzie przewidywał wystąpienie opadów na podstawie aktualnego wyglądu nieba, ale nie będzie to uczenie maszynowe. Uczeniem maszynowym będzie za to zgromadzenie dużej ilości zdjęć nieba, wraz z informacją, czy wystąpiły opady i przetworzenie tych danych przez jeden z algorytmów uczenia maszynowego (np. regresję logistyczną, KNN, sieć neuronową, itp.), w celu uzyskania modelu skutecznie przewidującego wystąpienie opadów.
Sieci neuronowe są jednym z algorytmów / sposobów uczenia maszynowego. Algorytm ten wykorzystuje struktury matematyczne w zachowaniu przypominające działania ludzkich neuronów. Takie sztuczne neurony, połączone w sieć, przyjmują sygnały na wejściu i wykonując na nich relatywnie prostą operację, emitują sygnał na wyjściu, który przesyłany jest do kolejnej warstwy neuronów lub do wyjścia sieci, jako wynik jej działania. Wejściem do sieci mogą być np. wartości poszczególnych pikseli ze zdjęcia nieba lub odpowiednio przetworzone do postaci cyfrowej dane aplikacji kredytowej.
Każdy sygnał wejściowy do sztucznego neuronu posiada wagę, która wzmacnia lub osłabia sygnał wyjściowy tegoż neuronu. W trakcie uczenia sieci, wykorzystując sprzężenie zwrotne, algorytm uczenia sieci neuronowej modyfikuje wagi przypisane do poszczególnych neuronów tak, aby odpowiedź sieci była obarczona jak najmniejszym błędem. Błąd oblicza się porównując odpowiedź sieci na zestaw danych (np. wygląd nieba) z odpowiedzią prawidłową – jest to tak zwane uczenie nadzorowane, o czym niżej. Do realizacji sprzężenia zwrotnego, czyli odpowiedniej korekcji wag neuronów wykorzystuje się metody obliczeniowe, w tym algorytmy spadku gradientowego, dzięki czemu sieć “uczy się” coraz lepiej rozpoznawać dane. To wszystko w nadziei na to, że pokazując sieci nowe dane, np. aktualny, a wcześniej nie widziany przez sieć wygląd nieba, otrzymamy poprawną prognozę.
I dochodzimy do głębokiego uczenia (deep learning) – fascynującej gałęzi uczenia maszynowego, wykorzystującej bardzo rozbudowane sieci neuronowe, ogromne – podkreślę to raz jeszcze – OGROMNE ilości danych i do niedawna nieosiągalne moce obliczeniowe, do nauczenia komputera rzeczy, które wydawały się jedynie w zasięgu ludzkiego umysłu. W ostatnich latach głębokie uczenie okazało się bardzo skuteczne w rozwiązywaniu problemów dotyczących rozpoznawania obrazów, mowy, szeroko pojętej interakcji z otoczeniem (roboty, samochody), ale także w medycynie, testowaniu gier, czy detekcji i zapobieganiu oszustwom.
Zależności między wyżej wymienionymi pojęciami ilustruje poniższy rysunek.
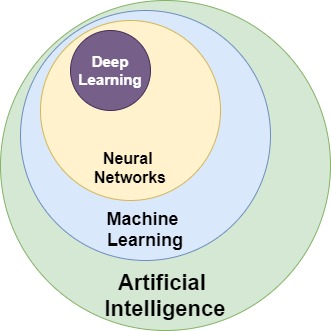
Uczenie nadzorowane a nienadzorowane
Skupiając się już tylko na uczeniu maszynowym, należy zwrócić uwagę, że rozróżniamy dwa typy uczenia: nadzorowane i nienadzorowane.
Uczenie nadzorowane jest jak praca dziecka z nauczycielem. Dziecko otrzymuje zestaw obrazków z informacją co jest na danym obrazku: tu jest koń, tu jest drzewo, tutaj auto – nazwijmy ten etap fazą uczenia. Po wystarczającej ilości prób można zapytać dziecko „co jest na obrazku?”, pokazując mu nieco inny samochód, inny gatunek drzewa lub konia o innym umaszczeniu. Moglibyśmy nazwać to fazą testowania, czy dziecko przyswoiło poprawnie pojęcia i co ważniejsze czy jest w stanie generalizować przyswojoną wiedzę. Innymi słowy, czy widząc drzewo, ale nie to samo co w fazie uczenia, jest w stanie nadal rozpoznać obiekt jako drzewo. Jeżeli nie jest, to proces uczenia powtarzamy do skutku.
Dla ludzi nadzorowany sposób uczenia jest naturalny i jesteśmy w tym bardzo dobrzy. W świecie cyfrowym uczenie nadzorowane opiera się o zbiór uczący, który z jednej strony pokazuje dane wejściowe, a z drugiej ich opis, nazywany często labelką lub celem (ang. label lub target). Dane wejściowe są z reguły mozolnie przygotowane uprzednio przez człowieka. Na przykład to człowiek opisuje każdy z dziesiątek tysięcy obrazków, których zamierza użyć w procesie nauki. Algorytm uczy się klasyfikować lub przewidywać wartości na podstawie danych wejściowych zbioru uczącego oraz labelek. Nauka przebiega na zasadzie kolejnych prób, oceny popełnionego błędu i sprzężenia zwrotnego, aby algorytm w razie potrzeby mógł skorygować swoje działanie. Następnie, tak wyuczonej maszynie możemy przedstawić zbiór danych bez targetu i zapytać o predykcję klasy lub wartości.
Uczenie nienadzorowane to jak praca bez nauczyciela. Otrzymujemy zestaw danych i naszym zadaniem jest ich pogrupowanie lub znalezienie pewnych struktur i zależności (czasami ukrytych), bez uprzedniego wskazania czego szukamy lub na jakie klasy mamy dane podzielić. Wyobraźmy sobie, że otrzymaliśmy grupę zdjęć różnych drobnoustrojów i nie znając się na biologii musimy je pogrupować, biorąc pod uwagę na przykład podobieństwa i różnice w wyglądzie lub obserwowalnym zachowaniu.
Dane wykorzystywane do uczenia nienadzorowanego nie muszą być opisane labelkami. Są zatem dużo prostsze do przygotowania niż dane do uczenia nadzorowanego. Niestety, uczenie nienadzorowane może być efektywnie wykorzystane w dość wąskich zastosowaniach. Przykładami jest klasteryzacja, która umożliwia podział zbioru danych na grupy podobnych danych lub tak zwane autoencodery, dzięki którym bez wiedzy o specyfice analizowanego zbioru możemy dokonać jego kompresji do postaci, która będzie zawierała bardziej wartościową informację (pozbawioną szumu).
Rodzaje zbiorów danych i overfitting
Omawiając powyżej sposoby uczenia nawiązywałem do dwóch rodzajów zbiorów: uczącego i testowego. Tak naprawdę mamy jeszcze jeden zbiór – walidacyjny. Warto chwilę poświęcić temu zagadnieniu.
Podział na takie trzy zbiory można dobrze wytłumaczyć poprzez analogię do nauki przedmiotu na studiach. W pierwszej fazie studentom przedstawiany jest materiał na wykładach. Studenci słuchają wykładowcy, robią notatki, starają się zrozumieć podane przykłady. Innymi słowy pracują na zbiorze uczącym. Pominę tu fakt, że wykłady są nieobowiązkowe, 😉 tu akurat nie jest to najlepsza analogia do uczenia maszynowego, gdzie fazy uczenia po prostu nie można pominąć.
W dalszej kolejności studenci idą na ćwiczenia, gdzie rozwiązują zagadnienia samodzielnie, ale nadal pod okiem wykładowcy. To praca na zbiorze walidacyjnym. Ma on pokazać jak dobrze student przyswoił wiedzę z wykładu, czy jego aktualne umiejętności są wystarczające i czy materiał należy dodatkowo wyjaśnić. Proces uczenia na zbiorze uczącym (wykład) i walidacyjnym (ćwiczenia) jest powtarzany wielokrotnie. W przypadku uczenia maszynowego musi być powtarzany dużo częściej, nawet dziesiątki lub setki tysięcy razy. W końcu nie od dziś wiadomo, że żadna maszyna nie jest tak efektywna jak student tuż przed kolokwium. 😉 Na koniec semestru następuje jednak ten jakże lubiany przez wszystkich studentów moment – egzamin. Ostateczne potwierdzenie umiejętności zdobytych na wykładach i ćwiczeniach. Student otrzymuje materiał, którego uprzednio nie widział i musi samodzielnie wykazać się odpowiednimi umiejętnościami. To praca na zbiorze testowym.
W zagadnieniu, które chcemy rozwiązać z wykorzystaniem jakiegoś wybranego algorytmu uczenia maszynowego, musimy mieć do dyspozycji zbiór danych – często bardzo duży. W praktyce zbiór taki dzielimy na zbiór uczący i testowy, z reguły w proporcji 80/20. Taki zabieg jest konieczny, aby po nauczeniu modelu móc ocenić, czy nabył on umiejętność generalizowania. Innymi słowy, czy prawidłowo oceni również dane, których nie widział w procesie nauki. Jeżeli nie wydzielimy zbioru testowego, nie będziemy w stanie określić, czy nauczony model dobrze rozwiązuje postawione przed nim zadanie, czy też po prostu nauczył się rozpoznawać dane ze zbioru uczącego i przy prezentacji całkowicie nowej danej już sobie tak dobrze nie poradzi.
Przy okazji: zjawisko, które występuje w sytuacji w której model zapamiętał zbiór uczący, zamiast go zgeneralizować nazywamy overfittingiem. Algorytm nadmiernie dopasował się do danych i przez to nie jest w stanie poradzić sobie równie dobrze z danymi spoza zbioru uczącego.
Często ze zbioru danych (najczęściej ze zbioru uczącego) wyodrębnia się dodatkowo zbiór walidacyjny. Algorytm nie uczy się na zbiorze walidacyjnym, a jedynie na uczącym, a zbiór walidacyjny używany jest do sprawdzenia efektów w trakcie nauki, w celu odpowiedniego dostosowania hiperparametrów modelu (o nich nieco dalej). Generalnie jest spore zamieszanie z definicją zbioru walidacyjnego. Różni specjaliści definiują go nieco inaczej. Różne biblioteki implementują podział w odmienny sposób. Ale ogólny sens pozostaje taki sam: zbiór walidacyjny, to ocena procesu nauki w jego trakcie.
Czy możemy wykorzystać zbiór walidacyjny jako zbiór testowy, aby ocenić skuteczność gotowego modelu? Niestety nie. Mimo, że zbiór walidacyjny nie jest bezpośrednio używany w procesie nauki, to poprzez oddziaływanie na hiperparametry modelu, ma on istotny wpływ na sposób jego działania i tym samym nie nadaje się do obiektywnej oceny skuteczności.
Czym są właściwie hiperparametry?
Skoro już kilkukrotnie nawiązaliśmy do hiperparametrów, to warto przyjrzeć się im nieco bliżej. Zanim jednak przejdziemy do hiperparametrów, warto ustalić czym są parametry modelu, bo rozróżnienie między nimi często nastręcza problemów.
Podstawowym celem uczenia maszynowego jest takie przetworzenie zbioru danych, aby powstał pewien model matematyczny, którego możemy potem użyć do predykcji. W trakcie konstrukcji modelu używamy algorytmów optymalizujących, tak aby predykcja modelu była jak najtrafniejsza. Algorytmy te działają w dużej mierze poprzez tuning szeregu zmiennych opisujących model. Zmienne te nazywamy parametrami modelu. Nie są one ustawiane ręcznie, lecz wynikają z analizy danych zbioru uczącego i ich automatycznej optymalizacji przez algorytm. Przykładem parametrów modelu są wagi przypisane poszczególnym neuronom w sieci neuronowej, a w przypadku regresji logistycznej będą to współczynniki ω wielomianu postaci
y =ω1*x1+ω2*x2+…+ωn*xn
definiującego n-wymiarową płaszczyznę, dzielącą dane na klasy.
W przeciwieństwie do parametrów modelu, hiperparametry są zewnętrzne wobec modelu i nie są wyznaczane na podstawie danych w zbiorze uczącym. Są z reguły ustalane przez człowieka nadzorującego budowę modelu, a ich optymalna wartość nie jest znana. Najczęściej są inicjalnie wyznaczane na podstawie najlepszych praktyk, a potem ich wartość może być odpowiednio dostosowana w zależności od wyników uczenia.
Przykładami hiperparametrów może być k, czyli ilość sąsiadów w algorytmie k-najbliższych sąsiadów, ilość warstw sieci neuronowej i ilość neuronów w każdej z warstw, czy tempo uczenia (ang. learning rate), które określa jak szybko poruszamy się po funkcji straty, aby znaleźć jej minimum.
Reasumując, parametry modelu są ustalane automatycznie na podstawie danych zbioru uczącego, a hiperparametry są ustalane ręcznie na podstawie dobry praktyk oraz wyników osiąganych przez model i ich podstawową rolą jest de facto zoptymalizowanie algorytmu, aby ten wyznaczył jak najlepsze parametry modelu.
Mam nadzieję, że niniejszy post przybliżył wam podstawowe pojęcia w zakresu sztucznej inteligencji i uczenia maszynowego. Ich dobre zrozumienie z całą pewnością pomoże w efektywnej dalszej nauce.
Masz pytanie? Zadaj je w komentarzu.
Spodobał ci się post? Będzie mi miło, gdy go polecisz.
Do zobaczenia wkrótce, przy okazji omawiania innego ciekawego tematu!
Czy oglądasz mecze NBA? Sprawdź mój darmowy serwis NBA Games Ranked i ciesz się oglądaniem wyłącznie dobrych meczów.
W artykule chyba wkradł się bład. Jest napisane „Proces uczenia na zbiorze testowym (wykład) i walidacyjnym (ćwiczenia) jest powtarzany wielokrotnie.”, a wcześniej jest wyjasnione że wykład odnosi się do zbioru uczącego.
Faktycznie, jest błąd. Poprawiłem – dzięki za zwrócenie uwagi!