
Rozpoznawanie kształtów, a w szczególności rozpoznawanie pisma odręcznego, to jeden z najwdzięczniejszych tematów dla każdego rozpoczynającego naukę AI. Powodów jest kilka, ale dwa najważniejsze to łatwość, z jaką możemy skorzystać z dobrze opracowanych gotowych zbiorów danych oraz możliwość wizualizacji tychże danych.
Z niniejszego tutoriala dowiesz się między innymi:
- Czym jest zbiór MNIST i jak najprościej załadować zbiór do dalszego użycia w bibliotece Keras?
- Jak zwizualizować elementy zbioru MNIST?
- Czym jest normalizacja danych i jak znormalizować zbiór MNIST?
- Jak zbudować prosty model gęsto połączonej sieci neuronowej używając biblkioteki Keras?
- Czym jest one-hot encoding?
- W jaki sposób wyuczyć model klasyfikacji danych ze zbioru MNIST?
- Oraz w jaki sposób ocenić skuteczność procesu uczenia?
Rozpoznawanie pisma odręcznego – zbiór MNIST
OK, już bez dalszej zwłoki bierzmy na warsztat jeden z prostszych i lepiej znanych zbiorów, czyli sławny MNIST. Zbiór składa się z 60.000 elementów w zbiorze treningowym i 10.000 w zbiorze testowym. Każdy element jest obrazkiem o rozmiarach 28 na 28 pikseli. Obrazki nie są kolorowe, więc dla każdego piksela mamy jedną wartość reprezentującą odcień szarości.
Tak wygląda próbka danych w tym zbiorze. W dalszej części posta przyjrzymy się również pojedynczym danym.

Wikipedia contributors, 'MNIST database’, Wikipedia, The Free Encyclopedia, 1 June 2019, 15:05 UTC, https://en.wikipedia.org/w/index.php?title=MNIST_database&oldid=899811825 [accessed 11 August 2019]
Na początek sprawa dość oczywista: musimy zaimportować potrzebne biblioteki oraz dane. Potrzebujemy numpy i oczywiście genialnego Kerasa, który odseparuje nas od dość trudnego kodowania w TensorFlow. Zauważ, że importujemy również zbiór mnist z keras.dataset. To bardzo wygodne i pozwoli się skupić na samym sposobie uczenia. Przy okazji: jeżeli potrzebujesz zbudować środowisko programistyczne, w którym będziesz mógł realizować prace opisane w tym poście, zapraszam do zapoznania się z postem Środowisko programistyczne dla uczenia maszynowego.
import numpy as npimport keras>>> Using TensorFlow backend.
from keras.datasets import mnist
Jak widać powyżej, keras domyślnie użył biblioteki Tensorflow. Jeżeli ktoś woli może dla odmiany skorzystać z Theano.
Importując mnist zyskujemy dostęp do kilku funkcji, w tym do load_data(). Pobiera ona zbiór MNIST z internetu, zapisuje go w katalogu użytkownika (dla Windows w podkatalogu /.keras/datasets), a następnie zwraca dwa tuple z numpy array.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
>>> Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz >>> 11493376/11490434 [==============================] - 5s 0us/step
Zmienna x_train zawiera obrazki, na których będziemy uczyć sieć neuronową. Mamy tu do czynienia z uczeniem nadzorowanym, więc aby sieć mogła się uczyć, musi dostać od nas informację, co jest na danym obrazku. Te informacje są w zmiennej y_train. Dane te będziemy nazywali mianem „etykiet” lub nieco bardziej z angielskiego „labelek”.
Zmienna x_test zawiera obrazki, na których będziemy sprawdzali, czy nauczona sieć neuronowa potrafi prawidłowo rozpoznać cyfrę, której wcześniej nie widziała (na której się nie uczyła). Aby sprawdzić, czy sieć neuronowa prawidłowo oceniła zawartość obrazka musimy mieć również etykiety dla zbioru testowego, które znajdują się w zmiennej y_test.
Wizualizacja elementów zbioru MNIST
Na początek zobaczmy, jaki kształt mają te zmienne.
x_train.shape>>> (60000, 28, 28)x_test.shape>>> (10000, 28, 28)
Dane treningowe zawierają zgodnie z oczekiwaniami 60.000 elementów, każdy z nich o rozmiarze 28 na 28 (pikseli). Danych testowych jest 10.000. W obu przypadkach mamy do czynienia z tablicami trójwymiarowymi, dla których pierwszy wymiar to kolejne próbki danych (łącznie odpowiednio 60000 i 10000), a kolejne dwa wymiary przechowują wartości pikseli dla każdej próbki (dla każdego obrazka).
Może zobaczmy sobie jeden z elementów zbioru treningowego (x_train) oraz przypisaną do niego etykietą (y_train). Do tego celu wykorzystamy bibliotekę matplotlib.pyplot, którą musimy uprzednio zaimportować.
import matplotlib.pyplot as plt%matplotlib inline
Zapis <<%matplotlib inline>> jest charakterystyczny dla Jupyter Notebook i informuje Jupytera, że wyniki mają być wyświetlane w oknie notebooka.
# Wyświetlmy 200 element ze zbioru treningowego i jego labelkę. element = 200plt.imshow(x_train[element])plt.show()

# Wyświetlmy labelprint("Label dla elementu", element,":", y_train[element])
>>> Label dla elementu 200 : 1
Jak widać jest to jedynka. Tu warto nadmienić, że zbiór MNIST nie jest przygotowany bezbłędnie. Zdarzają się klasyfikacje błędne lub wątpliwe. Z tego powodu stosując nawet najbardziej zaawansowane metody nauczania nie udaje się uzyskać 100% poprawności klasyfikacji na tym stosunkowo prostym i dobrze zdefiniowanym zbiorze. Dla przykładu rzućmy okiem na element 500.
element = 500plt.imshow(x_train[element])plt.show()print("Label dla elementu", element,":", y_train[element])
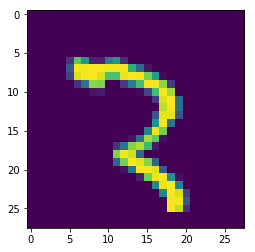
>>> Label dla elementu 500 : 3
To jest trójka? Czy może jednak dwójka? ;-). Ciężko w sumie powiedzieć.
Dość istotna kwestia: jeżeli przetwarzamy obraz w sieci neuronowej, to oczekuje ona wektora a nie nie tablicy dwuwymiarowej. Chyba, że dane mają trafić najpierw do konwolucji, ale o Convolutional Neural Networks w innym poście.
Przed dalszym przetwarzaniem powinniśmy zatem przekształcić zbiór treningowy do wymiaru 60000 na 784 (28*28). Aby zmienić kształt danych skorzystamy z funkcji reshape.
x_train = x_train.reshape((-1, 28*28))# To samo oczywiście dla zbioru testowego, choć zamiast 28*28 od razu podajemy wartość docelowąx_test = x_test.reshape((-1, 784))
Sprawdźmy czy dane zostały przekształcone właściwie.
x_train.shape>>> (60000, 784)
x_test.shape>>> (10000, 784)
Normalizacja danych
Jedną z wielu dobrych praktyk uczenia maszynowego jest normalizacja danych. Przed normalizacją wartość każdego piksela – dla przypomnienia oznaczająca poziom szarości danego piksela – powinna się zawierać między 0 (typowo przyjmuje się, że 0 to piksel całkowicie czarny) a 255 (piksel całkowicie biały). Wszystko co pomiędzy jest odcieniem szarości. Sprawdźmy to:
print(x_train.min(), "-", x_train.max())
>>> 0 - 255
Jest wiele sposobów na normalizację danych. Najczęściej spotyka się normalizację „zero-mean”, dla której nowa wartość W’ = (W – mean) / std. Czyli odjęcie średniej zbioru i podzielenie przez odchylenie standardowe. Taką normalizację stosuje się zwykle, kiedy nie są określone minimalne i maksymalne wartości w zbiorze. Ale my przecież wiemy, jakie są minimalne (0) i maksymalne (255) wartości, więc możemy zastosować normalizację „min-max”. Wzór na tę normalizację jest dosyć rozbudowany, choć prosty – zachęcam do poszukania. Niemniej, dla min = 0 i max = 255, możemy uprościć ten wzór znacząco i po prostu podzielić wartość każdego piksela przez wartość maksymalną czyli 255.
x_train = x_train / 255x_test = x_test / 255
Sprawdźmy zatem czy zgodnie z oczekiwaniami wartości maksymalne będą teraz oscylowały pomiędzy 0 a 1.
print(x_train.min(), "-", x_train.max())>>> 0.0 - 1.0
Rozpoznawanie pisma odręcznego – budujemy model
Na tym etapie mamy już przygotowane dane do uczenia: x_train i y_train oraz do testowania: x_test i y_test. Czas na uczenie i skorzystamy tu z biblioteki Keras. Na początek import modelu Sequential, o którym można poczytać tu: https://keras.io/getting-started/sequential-model-guide/ oraz dwóch rodzajów warstw: Dense i Dropout.
Dense to standardowa warstwa sieci neuronowej, w której każdy neuron jest połączony z każdym neuronem warstwy następnej.
Dropout to warstwa zapobiegająca zjawisku overfittingu, czyli nadmiernego dopasowania działania sieci neuronowej do danych treningowych. Jeżeli mamy do czynienia z overfittingiem, to po treningu sieć będzie uzyskiwać świetne rezultaty na zbiorze treningowym, a dużo gorsze na zbiorze testowym (w ogólności na danych uprzednio nie widzianych). Warstwa Dropout w każdym cyklu uczenia ignoruje losowo wybraną grupę neuronów, co powoduje, że sieć lepiej generalizuje.
W końcu importujemy przydatną funkcję to_categorical, która przyda nam się do one-hot encodingu labelek – o tym za chwilę.
# creating modelfrom keras.models import Sequentialfrom keras.layers import Dense, Dropoutfrom keras.utils import to_categorical
Model tworzymy podając kolejno dowolną ilość warstw sieci neuronowej. Możecie sobie wymyślić w zasadzie dowolną architekturę. Ja ograniczę się do 4 warstw typu Dense, przedzielonych warstwą Dropout. Tworząc model trzeba pamiętać o następujących kwestiach:
- każda warstwa ma swoją funkcję aktywacji. Funkcje aktywacji dostępne w Keras są wymienione tu: https://keras.io/activations/
- ostatnia warstwa musi mieć funkcję aktywacji odpowiednią dla zadania, jakie stawia się przed siecią. Jeżeli mamy do czynienia z regresją, czyli z sytuacją, gdy sieć neuronowa ma przewidzieć wartość (np. cenę domu), to funkcja aktywacji powinna być liniowa 'linear’, gdyż nie będzie ona przetwarzała w żaden sposób wyniku sieci. Jeżeli mamy do czynienia z klasyfikacją binarną, czyli chcemy aby sieć neuronowa wskazała czy mamy do czynienia z klasą A czy B (np. czy ktoś jest zagrożony rakiem płuc, czy nie), to użyjemy funkcji 'sigmoid’. Jeżeli mamy do czynienia z klasyfikacją wieloklasową (np. sklasyfikowanie obrazka do jednej z 10 klas – tak jak w naszym przypadku), użyjemy funkcji softmax. Softmax zwróci nam listę prawdopodobieństw przynależności próbki wejściowej do danej klasy. Na przykład dla wizualizowanego powyżej elementu 100 (jedynka) może to być następujący wektor: [0.02, 0.88, 0.003, 0.007, 0.01, 0.01, 0.035, 0.01, 0.005, 0.02] Jak widać najwyższe prawdopodobieństwo będzie na indeksie 1, odpowiadającym „jedynce”. Zwróćcie uwagę, że prawdopodobieństwa w naturalny sposób będą sumowały się do jedności.
- Keras oczekuje, że pierwsza warstwa zostanie poinformowana jaki jest kształt wektora wejściowego. Można do tego celu użyć parametru input_shape, który oczekuje tuple składającej się z wymiaru wektora wejściowego. Dla nas wektor jest jednowymiarowy stąd 784 i None. Drugą metodą jest skorzystanie z parametru wartwy Dense (inne warstwy go nie mają) input_dim=784. Wymiar wektora wejściowego podajemy tylko dla pierwszej warstwy, bo rozmiar wektorów wejściowych do kolejnych będzie wyliczony automatycznie na podstawie ilości neuronów w kolejnych warstwach
- każda warstwa jako pierwszy argument przyjmuje wielkość wektora wyjściowego dla warstwy. Jak widać z poniższego modelu pierwsza warstwa przyjmuje 784 parametry i wypuszcza na wyjściu 1024 parametry. Kolejna w naturalny sposób musi przyjąć 1024 (dlatego dla kolejnych nie musimy podawać wielkości wektora wejściowego) i emituje 128, itd.
- ilość warstw oraz wielkości wektorów wyjściowych z każdej warstwy są dowolne, należy jednak pamiętać, że ostatnia warstwa musi emitować: 1 wartość dla regresji (bo przewidujemy jedną wartość) lub n wartości dla klasyfikacji n-klasowej. Dla klasyfikacji binarnej będzie to 2. W naszym przypadku mamy 10 klas, więc jest to wartość 10.
model = Sequential([ Dense(1024, activation='relu', input_shape=(784,)), Dense(128, activation='tanh'), Dropout(rate=0.05), Dense(64, activation='relu'), Dense(10, activation='softmax')])
Po stworzeniu modelu należy go skompilować. W tym celu wywołujemy metodę compile podając:
- rodzaj optymalizatora: https://keras.io/optimizers/
- funkcję celu: https://keras.io/losses/
- i opcjonalnie metryki, które chcemy aby model rejestrował. W naszym przypadku użyjemy 'accuracy’
model.compile( optimizer='Adam', loss='categorical_crossentropy', metrics=['accuracy'])
Ostatnim elementem procesu uczenia jest wywołanie metody fit, która realizuje proces uczenia sieci neuronowej. Na wejściu podajemy przygotowany uprzednio zbiór treningowy (x_train), a ponieważ mamy do czynienia z uczeniem nadzorowanym (supervised learning), to podajemy również labelki (y_train). Dobrą praktyką jest przetasowanie danych, które zmniejsza ryzyko overfitting, stąd shuffle=True.
W uczeniu maszynowym często pojawia się parametr określany jako epochs – określa on ile razy zbiór treningowy zostanie wykorzystany w procesie uczenia. Tu, aby nauczyć sieć neuronową, przejdziemy zbiór treningowy 10 razy, czyli łącznie sieć zobaczy 600.000 próbek danych.
Ponieważ większość metod uczących nie używa algorytmu Gradient Descent ale jego lżejszej obliczeniowo wersji Stochastic, to należy podać również parametr batch_size, który określa jak często dokonujemy aktualizacji gradientu.
Czym jest one-hot encoding?
Gradient Descent to temat rzeka – niekoniecznie chcemy się tym teraz zajmować 🙂 . Musimy za to wyjaśnić tę linijkę kodu:
y=to_categorical(y_train)
Jeżeli w metodzie fit podamy po prostu y=y_train, to Keras zgłosi błąd:
>>>Error when checking target: expected dense_4 to have shape (10,) but got array with shape (1,)
Z czego on wynika? Jak już pisałem powyżej, ostatnią funkcją w naszej sieci jest softmax. Softmax zwróci nam listę prawdopodobieństw dla danej wejściowej. Na przykład dla wizualizowanego powyżej elementu 100 (jedynka) może to być następujący wektor:
[0.02, 0.88, 0.003, 0.007, 0.01, 0.01, 0.035, 0.01, 0.005, 0.02].
Jednocześnie w setnym elemencie tablicy y_train[100] mamy wartość 1. W jaki sposób sieć neuronowa miałaby porównać te dwie wartości, a następnie wyliczyć jak daleko jest od celu (gdzie celem jest zgodność wyniku klasyfikacji z etykietą)? Nie uda się tego zrobić bez przekształcenia targetu (labelek) do postaci tzw. one-hot-encoding. W rezultacie nasza „1” zostanie zapisana w postaci:
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
Gdybyśmy chcieli zapisać w ten sposób wartość 5, to wektor będzie wyglądał tak:
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0]
Tę operację przekształcenia skalara na wektor wykonuje właśnie funkcja to_categorical().
Uczenie i ocena skuteczności modelu
Na obecnym etapie jesteśmy już gotowi do uczenia sieci.
model.fit( x=x_train, y=to_categorical(y_train), epochs=10, batch_size=64, shuffle=True)
Całość uczenia zajęła około 200s i otrzymaliśmy accuracy wynoszącą 99,42%. Ponieważ uczenie nie trwa długo, możecie próbować pobawić się siecią – zmienić ilość epochs, batch_size, rodzaj optymalizatora, czy strukturę samej sieci.
Oczywiście wskazana wyżej accuracy uzyskana została na zbiorze treningowym. Teraz jest właśnie ten moment, kiedy przyda nam się zbiór testowy. Wynik na nim pewnie będzie nieznaczenie niższy, a jeżeli różnica byłaby większa niż 2 – 4 procent, to można zaryzykować stwierdzenie, że mamy do czynienia z overfittingiem i trzeba w modelu co nieco pozmieniać.
Aby ocenić skuteczność modelu, Keras daje nam do dyspozycji metodę evaluate.
eval = model.evaluate(x_test, to_categorical(y_test))>>>10000/10000 [==============================] - 1s 100us/step
eval>>>[0.07423182931467309, 0.9811]
Wynik przypisywany jest do zmiennej eval, która zawiera loss (tu: 0.074) i accuracy wynoszącą 98.11%. Różnica między accuracy na zbiorze treningowym i testowym wynosi tylko 1.31% i wydaje się akceptowalna.
Keras oferuje nam jeszcze jedną ciekawą metodę, którą można wykorzystać do przewidywania wartości dla nowych danych, których sieć jeszcze nie widziała. Ponieważ my uprzednio nie wydzieliliśmy takiego zbioru, a jedynie podzieliliśmy zbiór MNIST na dane uczące i testowe, to posłużymy się podzbiorem danych testowych.
predictions = model.predict(x_test[0:100])
Metoda zwróci 100-elementową tablicę wyników, w każdym elemencie będą podane prawdopodobieństwa, że dana wejściowa należy do danej klasy. Zobaczmy, jak wygląda przewidywanie dla x_test[0]
predictions[0]>>>array([3.7351333e-10, 2.8403690e-06, 3.6098727e-06, 2.9988249e-07,
1.5157393e-06, 5.1377755e-09, 1.6684153e-12, 9.9998987e-01,
1.9233731e-08, 1.7899656e-06], dtype=float32)
Jak widać większość wartości to bardzo małe liczby (bardzo małe prawdopodobieństwa, że obrazek należy do tej klasy), poza liczbą na pozycji 7 (liczonej od 0). Numpy ma bardzo użyteczną funkcję, która oszczędzi nasz wzrok i od razu poda nam, która klasa została przez model oceniona jako ta z najwyższym prawdopodobieństwem.
np.argmax(predictions[0])>>>7
Sprawdźmy zatem jak wygląda obrazek. Pamiętajmy, że dane wejściowe do sieci zostały spłaszczone na potrzeby nauki do wektora o długości 784. Przed wyświetleniem musimy je na powrót przekształcić do rozmiaru 28 x 28 pikseli.
plt.imshow(x_test[0].reshape(28,28))
Wygląda nieźle, prawda? 🙂 OK, to zobaczmy jak wyglądają wszystkie predykcje po potraktowaniu prawdopodobieństw funkcją argmax. Tu uwaga, ponieważ mamy tu do czynienia z tablicą dwuwymiarową, a nie wektorem jak przy poprzednim użyciu argmax, to musimy powiedzieć funkcji w jakim wymiarze ma przeanalizować dane. W naszym przypadku wzdłuż osi y, czyli axis=1.
np.argmax(predictions, axis=1)>>> array([7, 2, 1, 0, 4, 1, 4, 9, 6, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4, 0, 7, 4, 0, 1, 3, 1, 3, 4, 7, 2, 7, 1, 2, 1, 1, 7, 4, 2, 3, 5, 1, 2, 4, 4, 6, 3, 5, 5, 6, 0, 4, 1, 9, 5, 7, 8, 9, 3, 7, 4, 6, 4, 3, 0, 7, 0, 2, 9, 1, 7, 3, 2, 9, 7, 7, 6, 2, 7, 8, 4, 7, 3, 6, 1, 3, 6, 9, 3, 1, 4, 1, 7, 6, 9])
Ponieważ zbiór x_test[0:100] to nie są tak naprawdę nowe dane do predykcji i mamy dla nich określone labelki, to możemy je wyświetlić, aby porównać predykcje z rzeczywistością.
y_test[0:100]>>> array([7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4, 0, 7, 4, 0, 1, 3, 1, 3, 4, 7, 2, 7, 1, 2, 1, 1, 7, 4, 2, 3, 5, 1, 2, 4, 4, 6, 3, 5, 5, 6, 0, 4, 1, 9, 5, 7, 8, 9, 3, 7, 4, 6, 4, 3, 0, 7, 0, 2, 9, 1, 7, 3, 2, 9, 7, 7, 6, 2, 7, 8, 4, 7, 3, 6, 1, 3, 6, 9, 3, 1, 4, 1, 7, 6, 9], dtype=uint8)
Na pierwszy rzut oka wygląda to w zasadzie tak samo. Warto jednak napisać zgrabną formułkę, która wyliczy accuracy, bo dla 10, czy nawet 50 danych możemy to ocenić wzrokowo lub wyliczyć ręcznie, ale dla 1000 to już raczej nie większego sensu 🙂
Zastanówmy się, co porównujemy z czym? Na pewno porównujemy obie wyżej zapisane formuły, czyli:
np.argmax(predictions, axis=1) == y_test[0:100]>>>array([ True, True, True, True, True, True, True, True, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True])
OK, to jeszcze nie jest accuracy, a jedynie wskazanie, na których pozycjach przewidywania pokrywają się z rzeczywistością. Aby wyliczyć accuracy, skorzystamy z Numpy i jego funkcji mean, która na szczęście dobrze radzi sobie z różnymi typami danych, w tym z logicznymi. Finalna formułka:
np.mean(np.argmax(predictions, axis=1) == y_test[0:100])>>> 0.99
Przewidywania wytrenowanej przez nas sieci dla zbioru pierwszych 100 danych testowych mają accuracy 99%. Korci mnie, aby sprawdzić, gdzie model się pomylił, bo najwyraźniej w jednym miejscu się pomylił.
False jest traktowany jako 0 a True jako 1. Na szczęście mamy funkcję argmin, która również radzi sobie dobrze z danymi logicznymi:
wrong_pred = np.argmin(np.argmax(predictions, axis=1) == y_test[0:100])wrong_pred>>> 8element = wrong_predplt.imshow(x_test[element].reshape(28,28))plt.show()print("Label dla elementu", element,":", y_test[element])print("Predykcja dla elementu:", np.argmax(predictions[element]))
>>> Label dla elementu 8 : 5>>> Predykcja dla elementu: 6
Jak widać obrazek jest oznaczony jako 5, a dla sieci wygląda to jak 6. Przyznam się, że się nie dziwię. Prawdopodobnie jest to faktycznie piątka, dziwnie napisana, ale gdyby ktoś kazał mi stwierdzić „na szybko”, to być może postawiłbym na szóstkę.
Jeżeli uczenie trwało długo, co pewnie nie ma miejsca w tym przypadku, to warto model zapisać korzystając z metody save.
model.save(r'<<insert-full-path-here-and-name-a-file-as-you-wish>>')
Tym samym dotarliśmy do końca tutoriala – gratulacje! Rozpoznawanie pisma odręcznego jest złożonym zagadnieniem, ale korzystając z dobrze zdefiniowanego zbioru jakim jest MNIST i biblioteki Keras dość łatwo i szybko można osiągnąć całkiem dobre efekty. Zachęcam do dalszego zgłębiania zagadnienia oraz zapoznania się z innymi postami na moim blogu.
Masz pytanie? Zadaj je w komentarzu.
Spodobał ci się post? Będzie mi miło, gdy go polecisz.
Do zobaczenia wkrótce, przy okazji omawiania innego ciekawego tematu!
Witam, mnie bardziej interesuje nie tyle co klasyfikacji odręcznie pisanych liter/cyfr, a ich segmentacja. Czy jest to możliwe za pomocą sieci neuronowych? Coś na ten temat czytałem (przyznam, że niewiele), bo mam inne przedmioty do zaliczenia na studiach ale zastanawiam się czy istnieje opis matematyczny np. sieci rekurencyjnej, która byłąby w stanie segmentować treść odręcznie pisaną np. ciąg liter (zakładamy, że nie są połączone ze sobą). Oczywiście pomijam tutaj metode Otsu i generowanie histogramu do segmentacji, mi bardziej chodzi o to, czy można sobie poradzić z tym wykorzystując jedynie sieci konwolucjny czy jakiekolwiek inne i z jaką dokłądnością. Może Pan pokierować mnie na jakieś pojęcia, które przydałyby mi się w realizacji OCR?
Nie zajmowałem się takimi zagadnieniami, więc niestety nie pomogę. Powodzenia!